Cloud Patterns: Storage, Serverless, and Coordination
EE 547 - Unit 9
Horizontal Scaling Breaks Local Storage Assumptions
Single instance architecture
All requests handled by same instance, all file operations see same filesystem state.
Instance A
├── /data/models/classifier.pkl
├── /data/uploads/user_files/
└── /data/cache/Multiple instance architecture
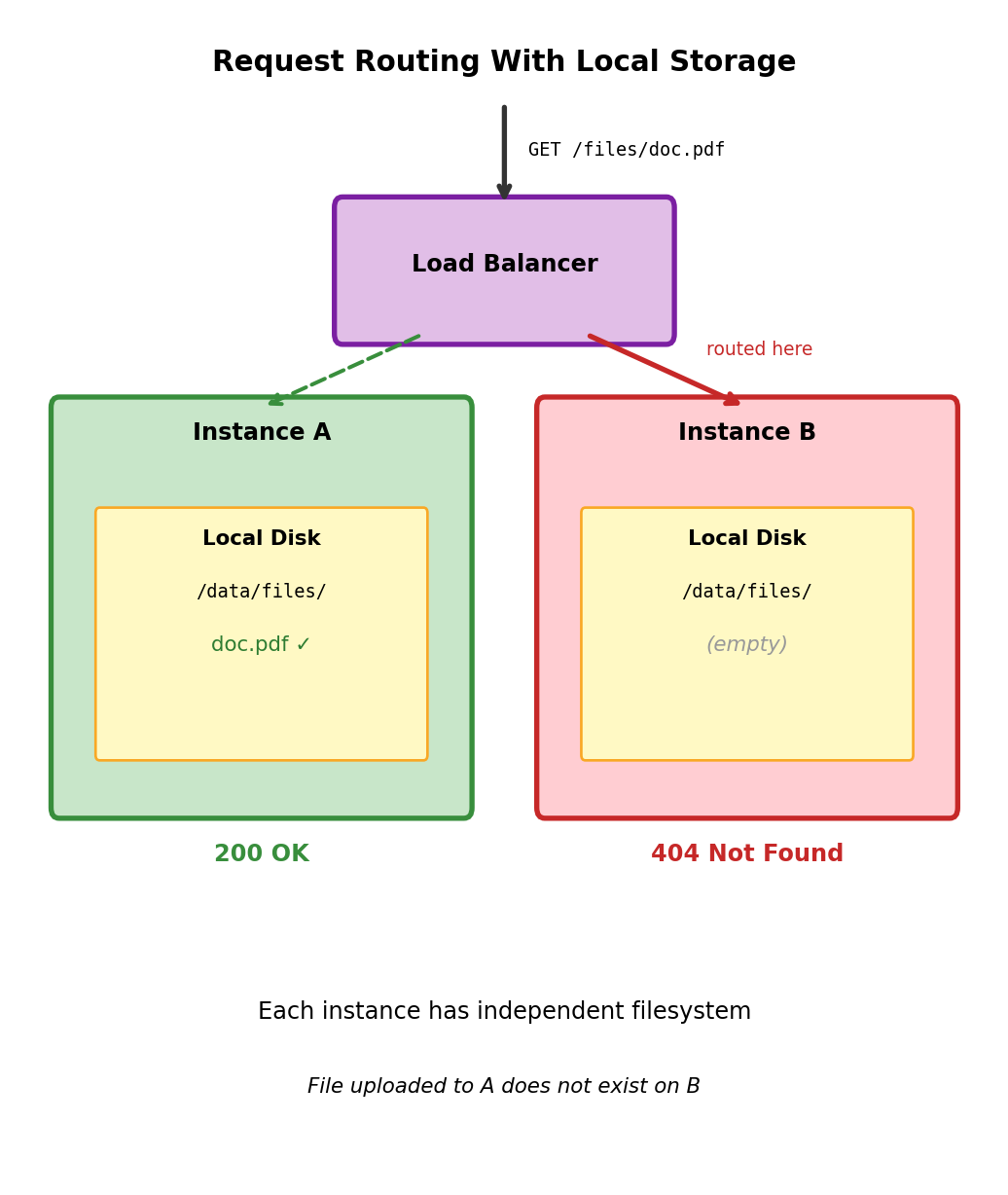
Load balancer distributes requests. Each instance has independent local filesystem.
Instance A Instance B
├── /data/models/ ├── /data/models/
│ └── classifier.pkl │ └── (empty)
└── /data/uploads/ └── /data/uploads/
└── file1.pdf └── (empty)Request uploads file to Instance A. Subsequent request routed to Instance B. File does not exist - FileNotFoundError.
Model deployed to Instance A. Instance B cannot serve predictions - model not present.
Fundamental issue: Local filesystem is instance-scoped, but application logic assumes shared state across all request handlers.
Storage Must Exist Independent of Compute Instances
Three abstractions provide instance-independent storage with different access models:
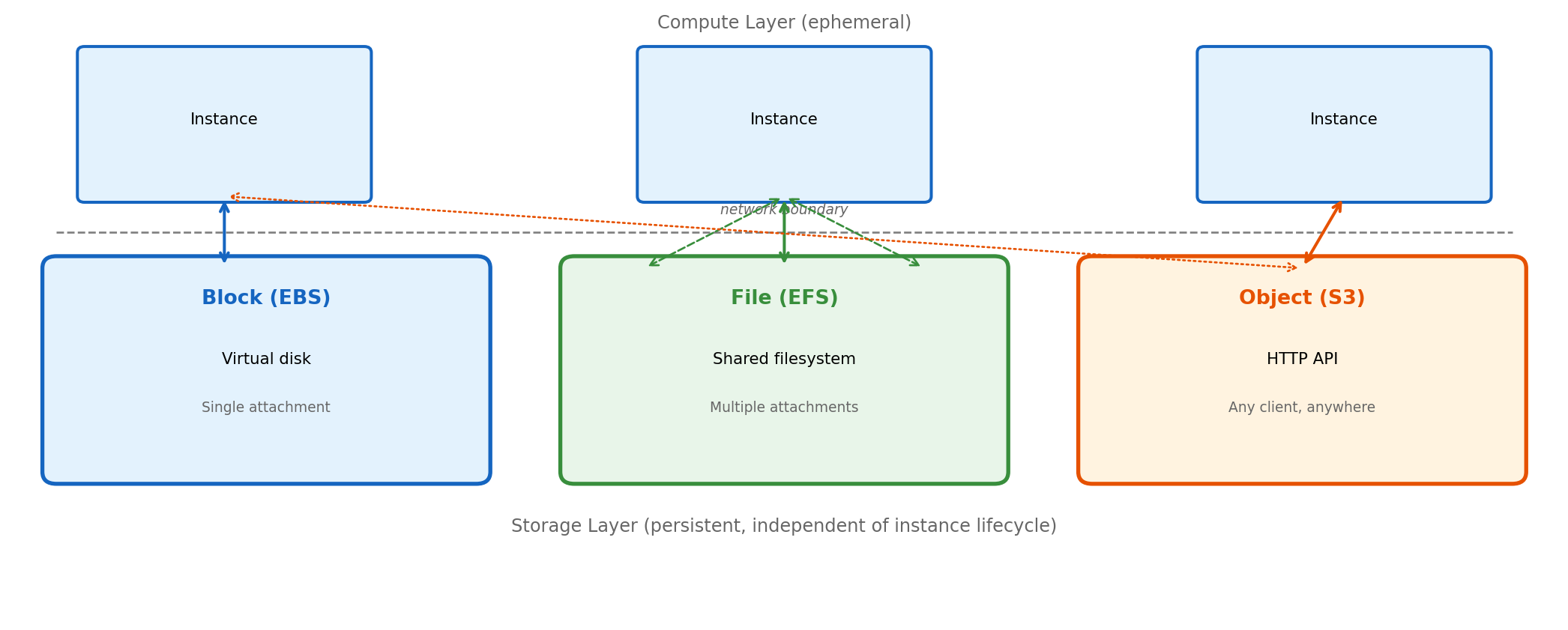
Block storage presents a virtual disk device. Instance mounts it as filesystem, uses standard file operations. One instance attachment at a time (with limited exceptions).
File storage provides shared filesystem via network protocol (NFS). Multiple instances mount simultaneously, see same files, coordinate via filesystem semantics.
Object storage exposes HTTP API for storing and retrieving blobs by key. No filesystem abstraction - operations are PUT, GET, DELETE over HTTPS. Accessible from any network location.
Each model trades capabilities for constraints. Selection depends on how application accesses data.
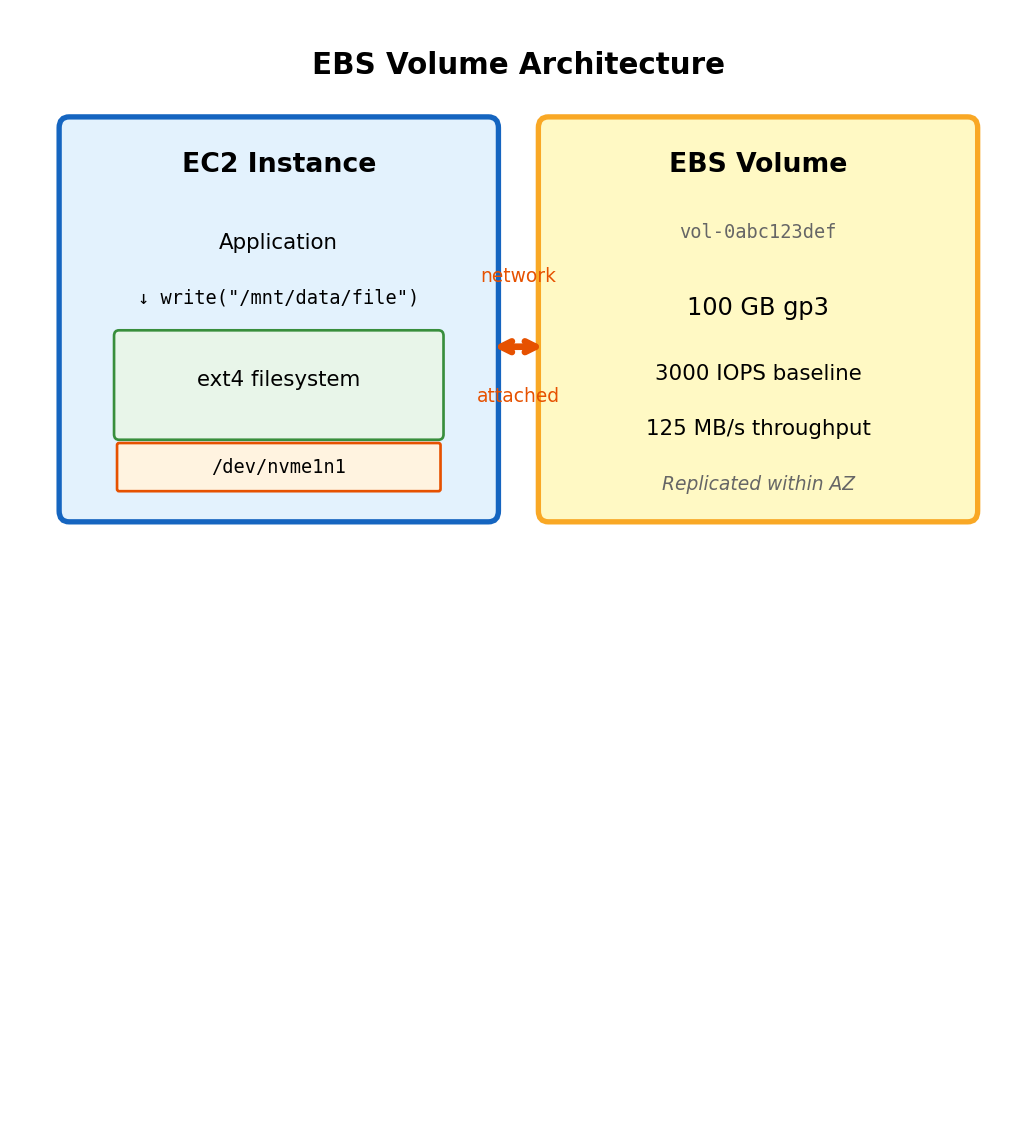
Block Storage Provides Virtual Disk Device
EBS volume appears as block device to instance
# List block devices - EBS volume appears as nvme device
$ lsblk
NAME SIZE TYPE
nvme0n1 8G disk # Root volume
└─nvme0n1p1 8G part /
nvme1n1 100G disk # Attached EBS volumeThe volume is a raw block device - bytes addressable by sector. No filesystem until you create one.
Preparing new volume for use:
# Create partition table (GPT for volumes > 2TB)
$ sudo parted /dev/nvme1n1 mklabel gpt
# Create single partition spanning volume
$ sudo parted /dev/nvme1n1 mkpart primary 0% 100%
# Create ext4 filesystem on partition
$ sudo mkfs.ext4 /dev/nvme1n1p1
# Create mount point and mount
$ sudo mkdir /mnt/data
$ sudo mount /dev/nvme1n1p1 /mnt/data
# Verify
$ df -h /mnt/data
Filesystem Size Used Avail Use% Mounted on
/dev/nvme1n1p1 98G 61M 93G 1% /mnt/dataAfter mounting, /mnt/data behaves as normal directory. Application reads and writes files without awareness of underlying EBS volume.
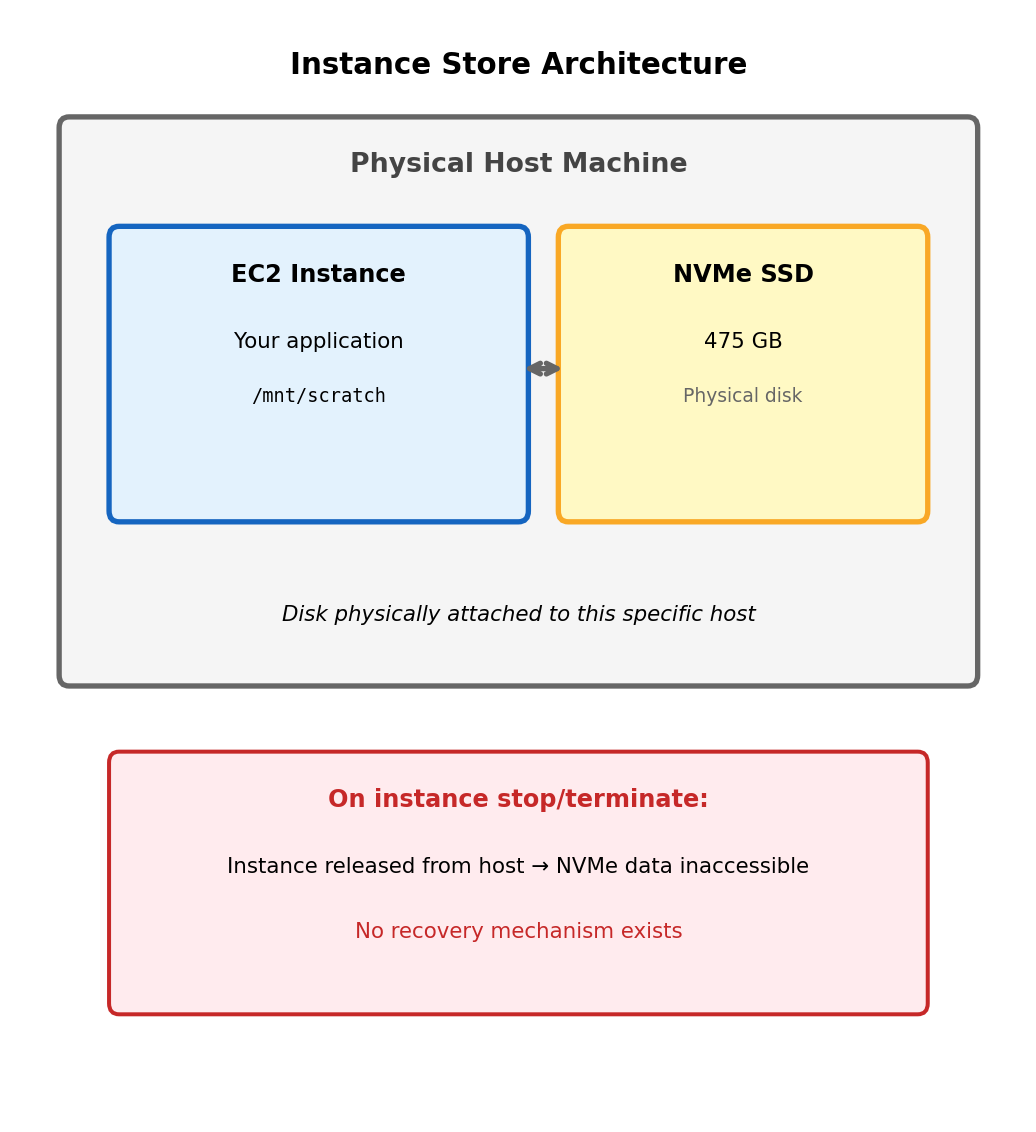
EBS characteristics:
- Persists independently of instance (survives stop/terminate)
- Snapshots to S3 for backup and replication
- Resizable while attached (extend filesystem after)
- Latency: sub-millisecond (network-attached, same AZ)
Persistent Mount Configuration
Mount persists only until reboot
The mount command attaches filesystem for current session. After instance reboot, volume is still attached but not mounted.
# After reboot
$ df -h /mnt/data
df: /mnt/data: No such file or directory
# Volume still attached, just not mounted
$ lsblk
NAME SIZE TYPE
nvme1n1 100G disk # Present but not mountedConfigure automatic mount via fstab:
# Get volume UUID (stable identifier)
$ sudo blkid /dev/nvme1n1p1
/dev/nvme1n1p1: UUID="a1b2c3d4-..." TYPE="ext4"
# Add entry to /etc/fstab
$ echo 'UUID=a1b2c3d4-... /mnt/data ext4 defaults,nofail 0 2' | \
sudo tee -a /etc/fstab
# Test fstab entry (mount all entries)
$ sudo mount -a
# Verify
$ df -h /mnt/dataThe nofail option allows instance to boot even if volume attachment fails - prevents boot hang if volume is detached.
Complete EBS setup sequence
# 1. Identify the new volume
lsblk
# 2. Create partition table
sudo parted /dev/nvme1n1 mklabel gpt
sudo parted /dev/nvme1n1 mkpart primary 0% 100%
# 3. Create filesystem
sudo mkfs.ext4 /dev/nvme1n1p1
# 4. Create mount point
sudo mkdir -p /mnt/data
# 5. Get UUID for fstab
VOLUME_UUID=$(sudo blkid -s UUID -o value /dev/nvme1n1p1)
# 6. Add to fstab for persistent mount
echo "UUID=$VOLUME_UUID /mnt/data ext4 defaults,nofail 0 2" | \
sudo tee -a /etc/fstab
# 7. Mount (using fstab entry)
sudo mount -a
# 8. Verify
df -h /mnt/data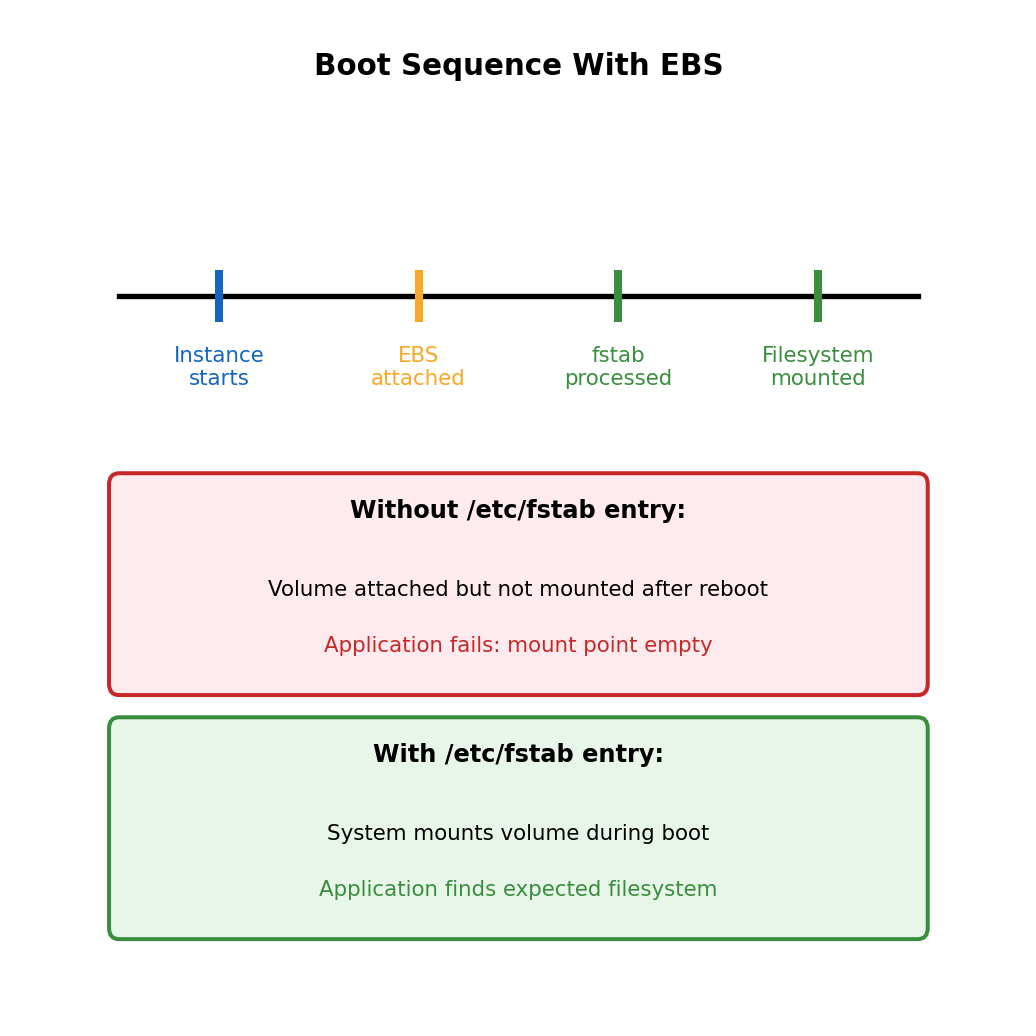
UUID vs device path:
Device names (/dev/nvme1n1) can change between boots depending on attachment order. UUID is stable identifier assigned when filesystem is created.
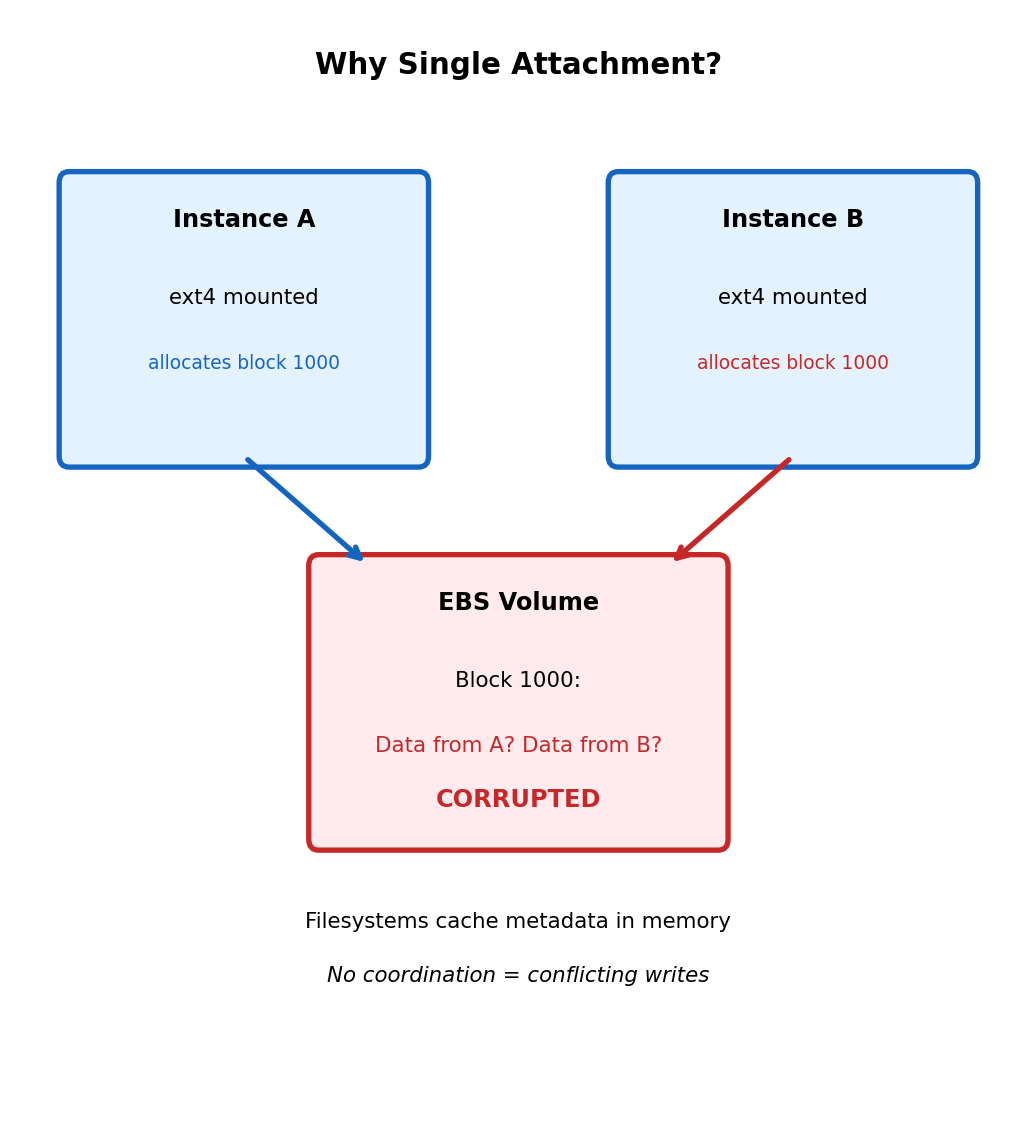
Block Storage Single-Attachment Constraint
Standard EBS volumes attach to one instance at a time
Attempt: Attach vol-0abc123 to Instance B
(currently attached to Instance A)
Error: Volume vol-0abc123 is in 'in-use' state
attached to instance i-0111222333Filesystem design assumes exclusive access
Filesystems like ext4 maintain metadata structures:
- Superblock: filesystem parameters
- Inode tables: file metadata
- Block allocation bitmaps: which blocks are free
These structures are cached in memory and written back to disk. Two instances mounting same volume:
- Instance A allocates block 1000 for new file
- Instance B (unaware) allocates block 1000 for different file
- Both write different data to same location
- Filesystem corruption guaranteed
EBS Multi-Attach (io1/io2 volumes only)
Multi-Attach allows attaching io1 or io2 volume to up to 16 instances. These are provisioned IOPS SSD volumes designed for high-performance workloads.
Requires cluster-aware filesystem (not ext4):
- Shared-disk filesystems: GFS2, OCFS2
- Application-level coordination: Clustered databases
Not general-purpose shared storage - specialized use case requiring explicit coordination.
Standard filesystems cannot coordinate across multiple hosts - they assume single writer.
File Storage Shares Filesystem Across Network
Network filesystem architecture
EFS (Elastic File System): Managed NFS service. Multiple instances connect to shared network endpoint (not attached like block storage).
# Mount EFS filesystem (NFS protocol)
$ sudo mount -t nfs4 \
-o nfsvers=4.1,rsize=1048576,wsize=1048576 \
fs-0123456789.efs.us-east-1.amazonaws.com:/ \
/mnt/sharedMount target fs-0123456789.efs.us-east-1.amazonaws.com: DNS name resolving to EFS infrastructure within VPC.
File operations traverse network
# Write on Instance A
with open('/mnt/shared/config.json', 'w') as f:
json.dump(config, f)
# Read on Instance B (same filesystem)
with open('/mnt/shared/config.json', 'r') as f:
config = json.load(f) # Sees Instance A's writeEvery read and write is a network operation to EFS service. The filesystem appears local but data travels over network.
NFS protocol handles coordination:
- File locking across clients
- Cache coherency
- Concurrent access semantics
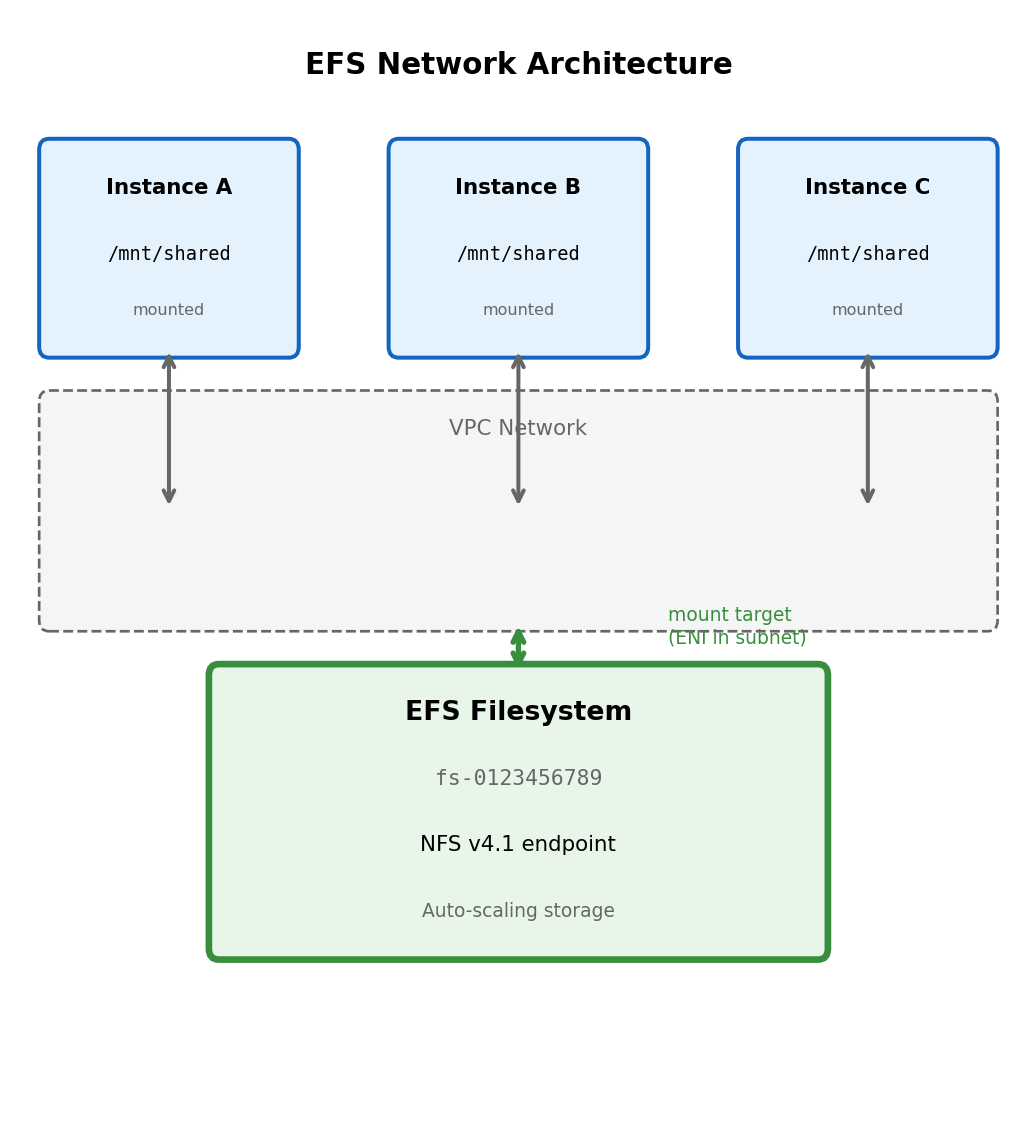
All instances connect to same EFS endpoint. Filesystem state is centralized in EFS service.
Network Filesystem Performance Characteristics
Latency comparison with local storage
| Storage Type | Read Latency | Write Latency |
|---|---|---|
| Instance store (NVMe) | ~0.1 ms | ~0.1 ms |
| EBS gp3 | ~1-2 ms | ~1-2 ms |
| EFS General Purpose | ~5-10 ms | ~5-10 ms |
| EFS Max I/O | ~10-25 ms | ~10-25 ms |
Every EFS operation crosses network, adds latency overhead compared to locally-attached storage.
Throughput scales with data size
EFS throughput depends on data stored:
- Bursting mode: Baseline throughput + burst credits
- Provisioned mode: Fixed throughput regardless of size
Data stored: 100 GB
Baseline: 5 MB/s (bursting mode)
Burst: Up to 100 MB/s (while credits available)
Data stored: 1 TB
Baseline: 50 MB/sSmall file operations
NFS protocol overhead per operation. Many small files = many round trips.
# Slow: 1000 small file reads
for i in range(1000):
with open(f'/mnt/efs/file_{i}.txt') as f:
data = f.read() # Network round trip each
# Faster: Single large file
with open('/mnt/efs/large_file.bin') as f:
data = f.read() # One operation, streams data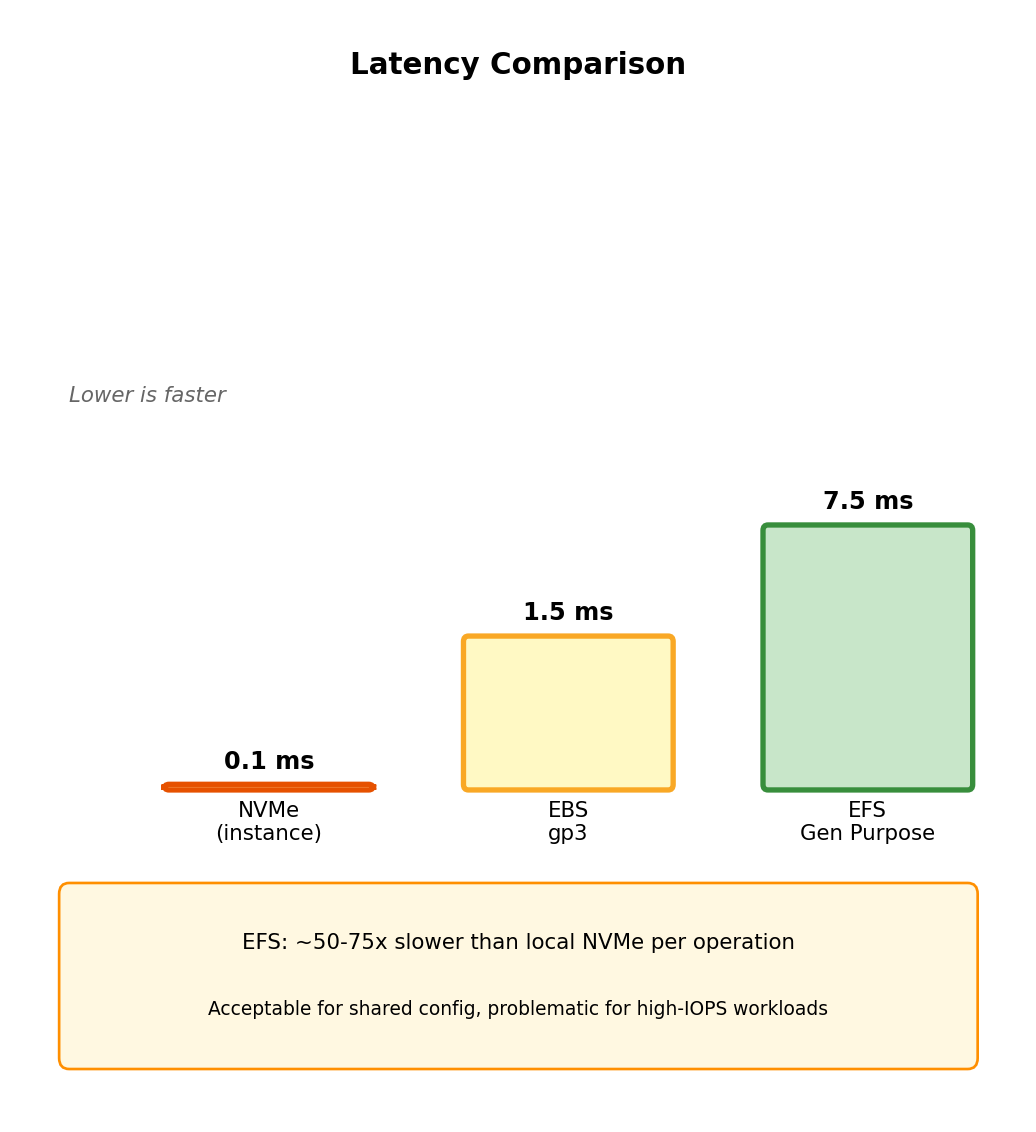
EFS appropriate for: Shared configuration, content management, home directories.
Not appropriate for: Databases, high-throughput processing, latency-sensitive applications.
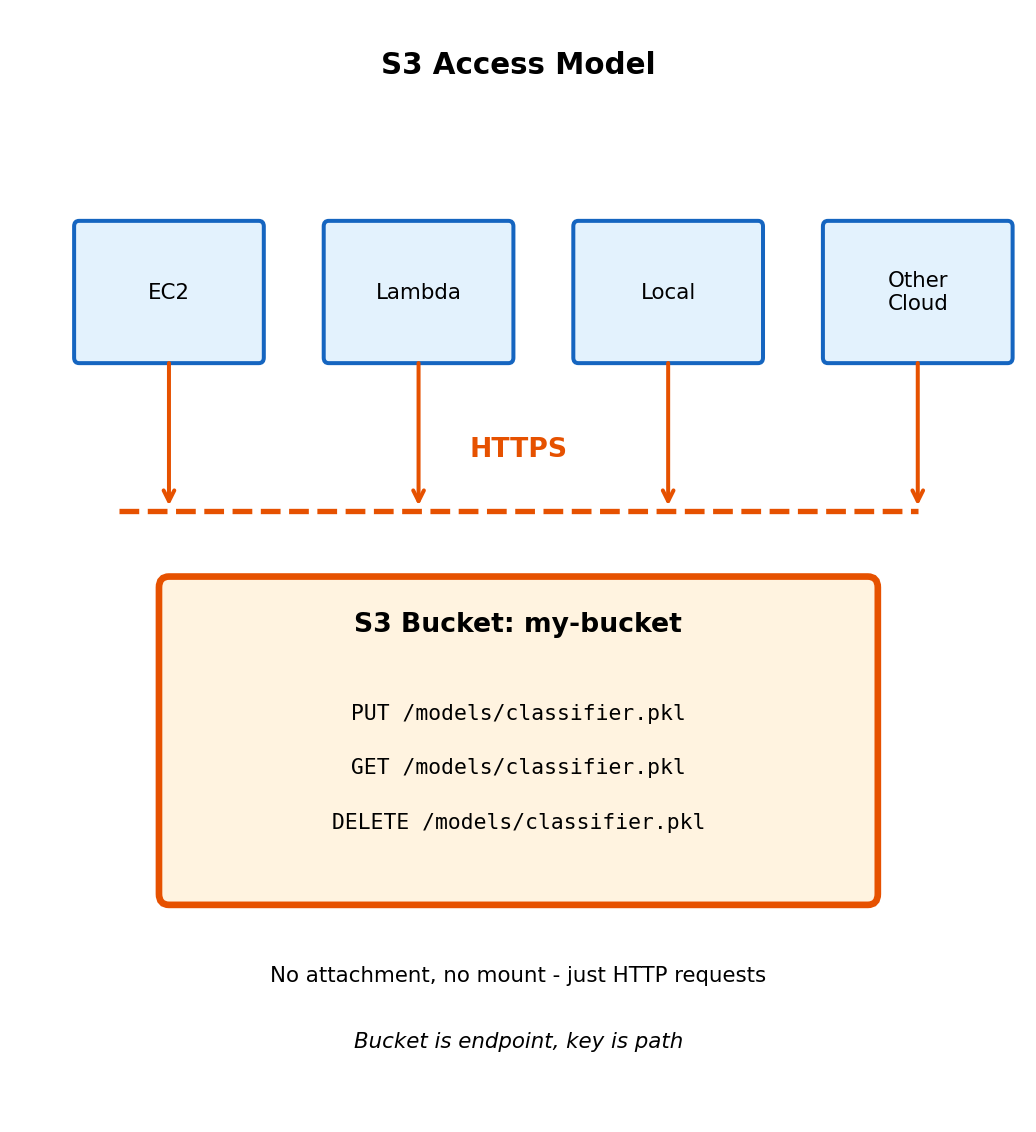
Object Storage Uses HTTP API Instead of Filesystem
S3 operations are HTTP requests
import boto3
s3 = boto3.client('s3')
# PUT object (HTTP PUT request)
s3.put_object(
Bucket='my-bucket',
Key='models/classifier.pkl',
Body=open('model.pkl', 'rb')
)
# GET object (HTTP GET request)
response = s3.get_object(
Bucket='my-bucket',
Key='models/classifier.pkl'
)
data = response['Body'].read()
# DELETE object (HTTP DELETE request)
s3.delete_object(
Bucket='my-bucket',
Key='models/classifier.pkl'
)No filesystem - HTTP semantics:
- Address by bucket + key (like URL path)
- No mount, no file handles
- No directories (keys can contain
/but it’s just a character) - No append (rewrite entire object)
- No rename (copy to new key, delete old)
- No locking (last write wins)
Accessible from anywhere with network:
EC2 instance, Lambda function, laptop, any HTTP client. No attachment, no VPC requirement (with public endpoint).
S3 Keys Are Flat Namespace With Path-Like Convention
Console displays folder hierarchy - API stores flat keys
AWS Console shows:
my-bucket/
├── models/
│ ├── v1/
│ │ └── classifier.pkl
│ └── v2/
│ └── classifier.pkl
└── uploads/
└── user123/
└── document.pdfActual S3 contents (three objects, flat):
Key: models/v1/classifier.pkl
Key: models/v2/classifier.pkl
Key: uploads/user123/document.pdfNo “models” folder exists. The / characters are part of the key string, not directory separators.
Listing with prefix filter:
# "List directory contents" = list objects with prefix
response = s3.list_objects_v2(
Bucket='my-bucket',
Prefix='models/'
)
for obj in response['Contents']:
print(obj['Key'])
# models/v1/classifier.pkl
# models/v2/classifier.pklDelimiter simulates directory listing:
response = s3.list_objects_v2(
Bucket='my-bucket',
Prefix='models/',
Delimiter='/'
)
# CommonPrefixes: ['models/v1/', 'models/v2/']
# Returns "subdirectory" prefixes without listing all objects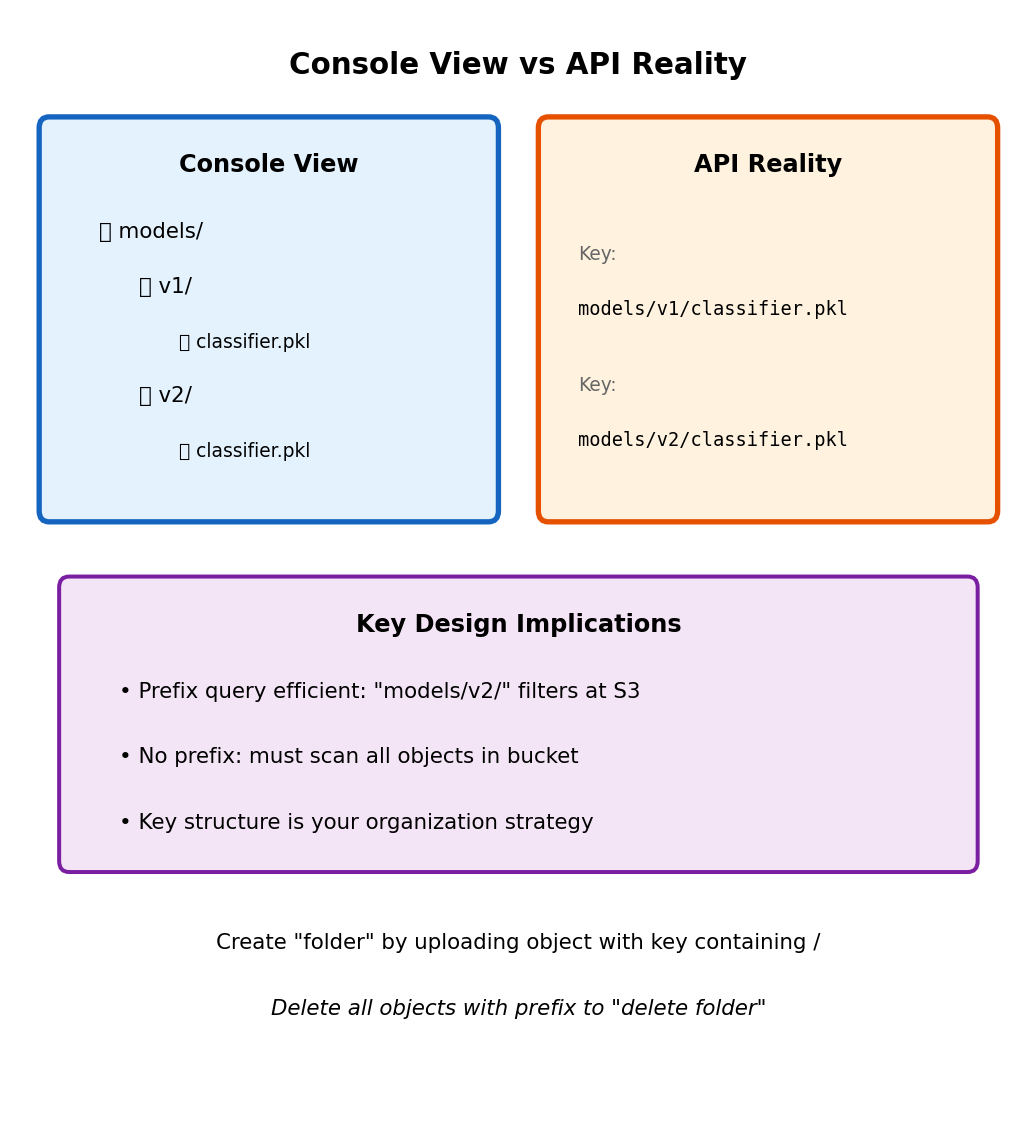
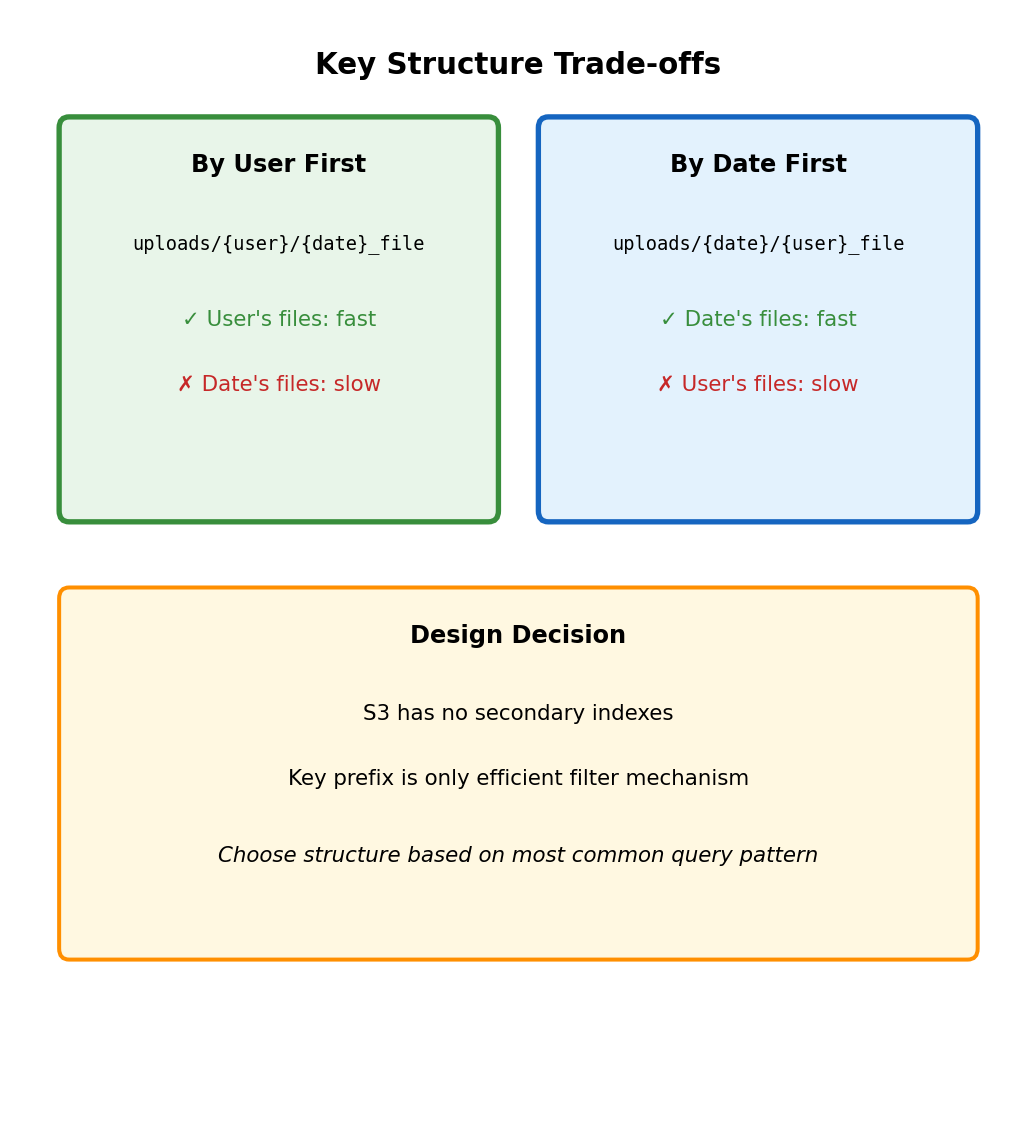
S3 Key Design Affects Query Efficiency
Key prefix determines what queries are efficient
# Key structure: {type}/{user_id}/{timestamp}_{filename}
# Example: uploads/user123/2025-01-15_document.pdf
# Efficient: All uploads for specific user
s3.list_objects_v2(
Bucket='app-data',
Prefix='uploads/user123/'
)
# S3 filters at storage layer, returns only matching objects
# Inefficient: All uploads from specific date
# No prefix helps - must scan all objects, filter client-side
response = s3.list_objects_v2(Bucket='app-data', Prefix='uploads/')
for obj in response['Contents']:
if '2025-01-15' in obj['Key']:
# Found oneAlternative key structure for date queries:
# Key structure: {type}/{date}/{user_id}_{filename}
# Example: uploads/2025-01-15/user123_document.pdf
# Now efficient: All uploads from specific date
s3.list_objects_v2(
Bucket='app-data',
Prefix='uploads/2025-01-15/'
)
# Now inefficient: All uploads for specific user
# Must scan all datesChoose key structure based on primary access pattern. Cannot efficiently query by both user and date with single key structure.
Secondary access patterns may require maintaining separate key hierarchies (duplication) or external index (database).
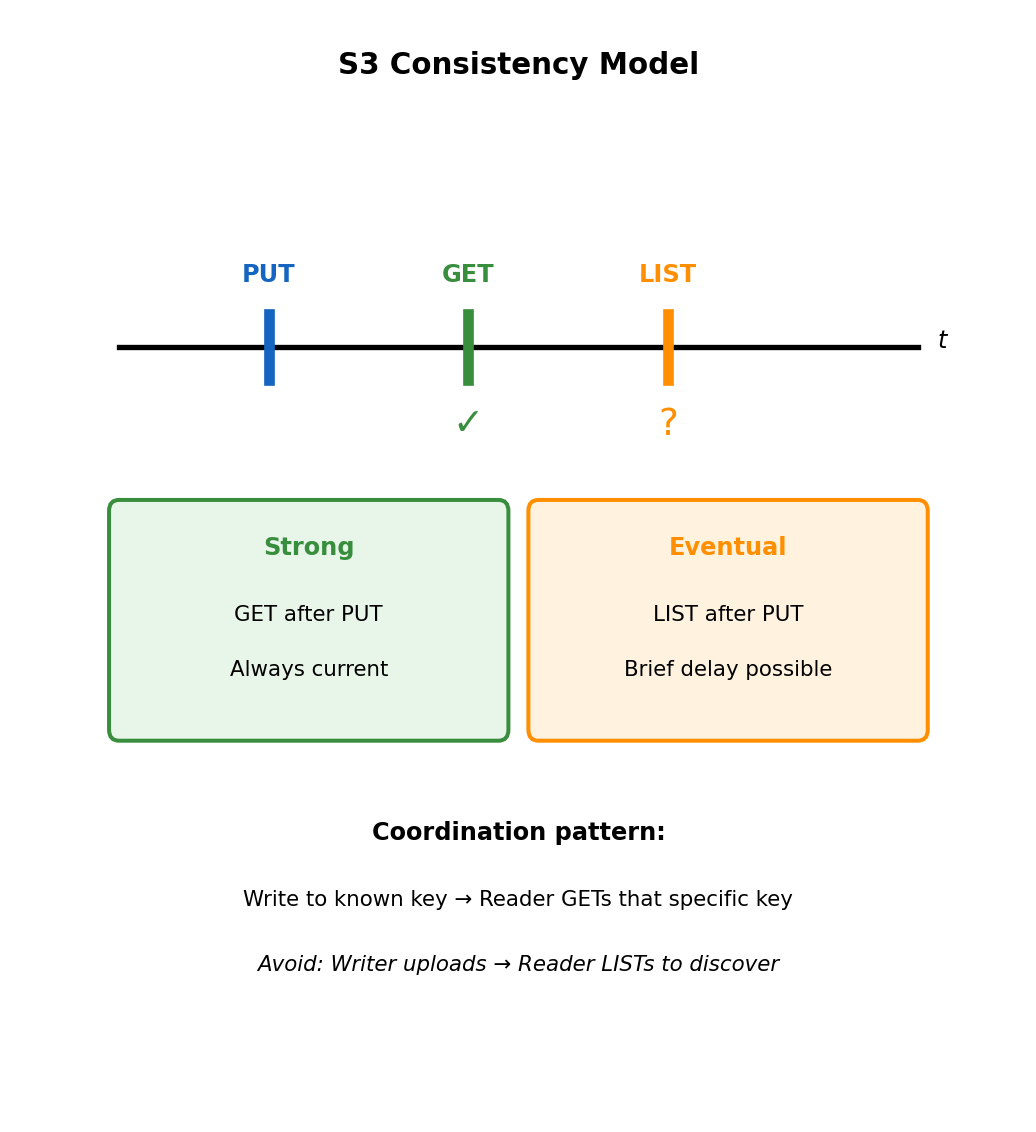
S3 Provides Strong Read-After-Write Consistency
Write then read returns current data
# Process A: Write object
s3.put_object(
Bucket='data',
Key='results/job-123.json',
Body=json.dumps({'status': 'complete', 'score': 0.94})
)
# Process B: Read immediately after
response = s3.get_object(
Bucket='data',
Key='results/job-123.json'
)
result = json.loads(response['Body'].read())
# Guaranteed to see Process A's writeConsistency guarantees:
| Operation Sequence | Guarantee |
|---|---|
| PUT → GET (same key) | Strong: sees new data |
| DELETE → GET | Strong: returns 404 |
| PUT → LIST | Eventual: may not appear immediately |
| Overwrite → GET | Strong: sees new version |
LIST operations may lag briefly
# Upload new object
s3.put_object(Bucket='data', Key='new-file.json', Body='{}')
# Immediate LIST might not include it
response = s3.list_objects_v2(Bucket='data', Prefix='')
# new-file.json may not appear in Contents yet
# But direct GET works immediately
s3.get_object(Bucket='data', Key='new-file.json') # SucceedsFor coordination between processes, use direct GET with known key rather than LIST to discover objects.
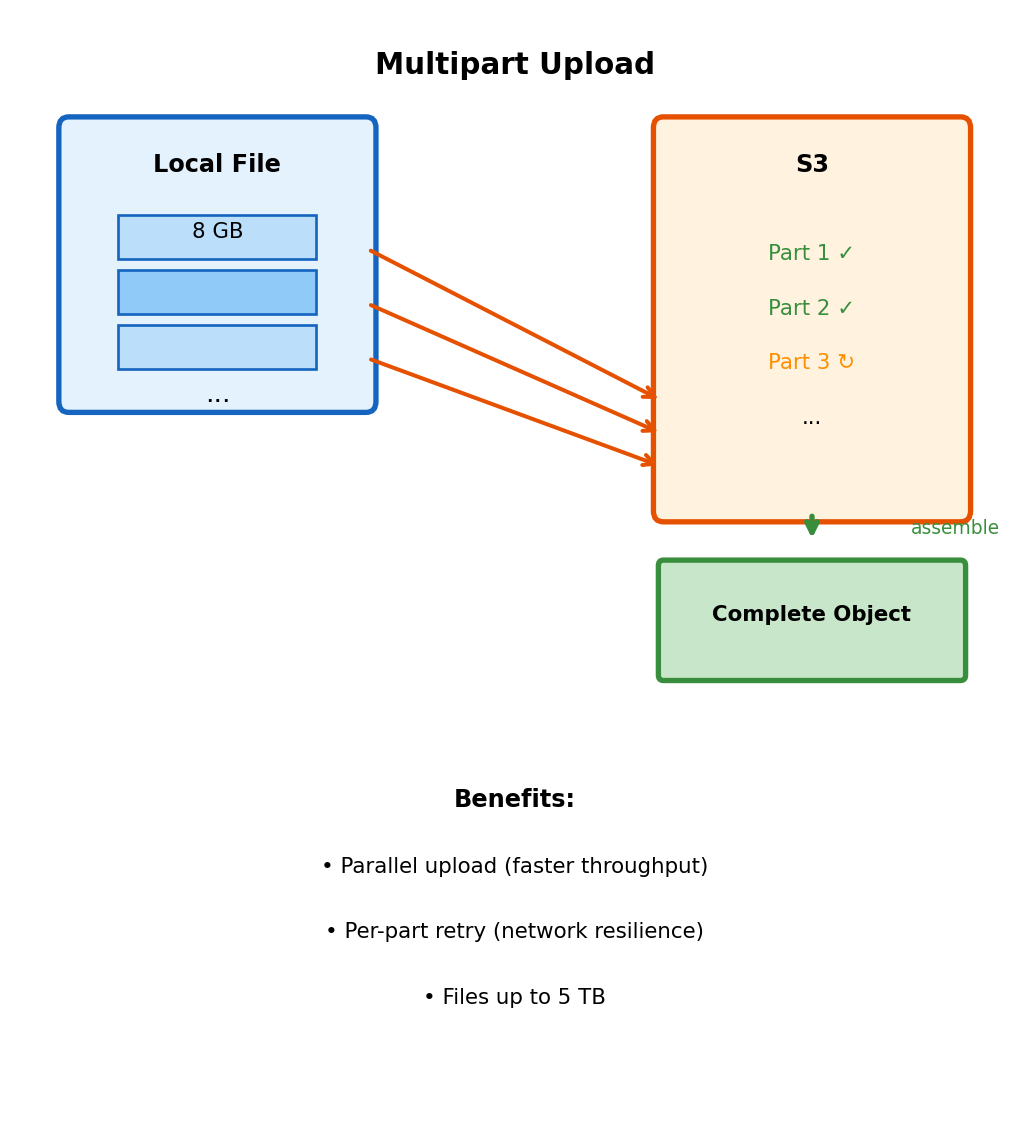
Uploading Large Files: Multipart Upload
Single PUT has limits and reliability issues
- Maximum single PUT: 5 GB
- Large uploads over unreliable networks: Failure requires restart from beginning
- No parallelization: Single stream to S3
Multipart upload splits file into parts
# boto3 handles multipart automatically for large files
s3.upload_file(
Filename='large_model.tar.gz', # 8 GB file
Bucket='ml-artifacts',
Key='models/large_model.tar.gz'
)
# Automatically uses multipart for files > 8 MB (configurable)Multipart mechanics:
- Initiate multipart upload → receive UploadId
- Upload parts (5 MB - 5 GB each) with part numbers
- Parts can upload in parallel, retry individually
- Complete upload → S3 assembles parts into single object
# Explicit multipart control
from boto3.s3.transfer import TransferConfig
config = TransferConfig(
multipart_threshold=100 * 1024 * 1024, # Use multipart > 100 MB
multipart_chunksize=50 * 1024 * 1024, # 50 MB parts
max_concurrency=10 # 10 parallel uploads
)
s3.upload_file('huge_file.bin', 'bucket', 'key', Config=config)Failed part retries only that part, not entire file. Parallel uploads improve throughput on high-bandwidth connections.
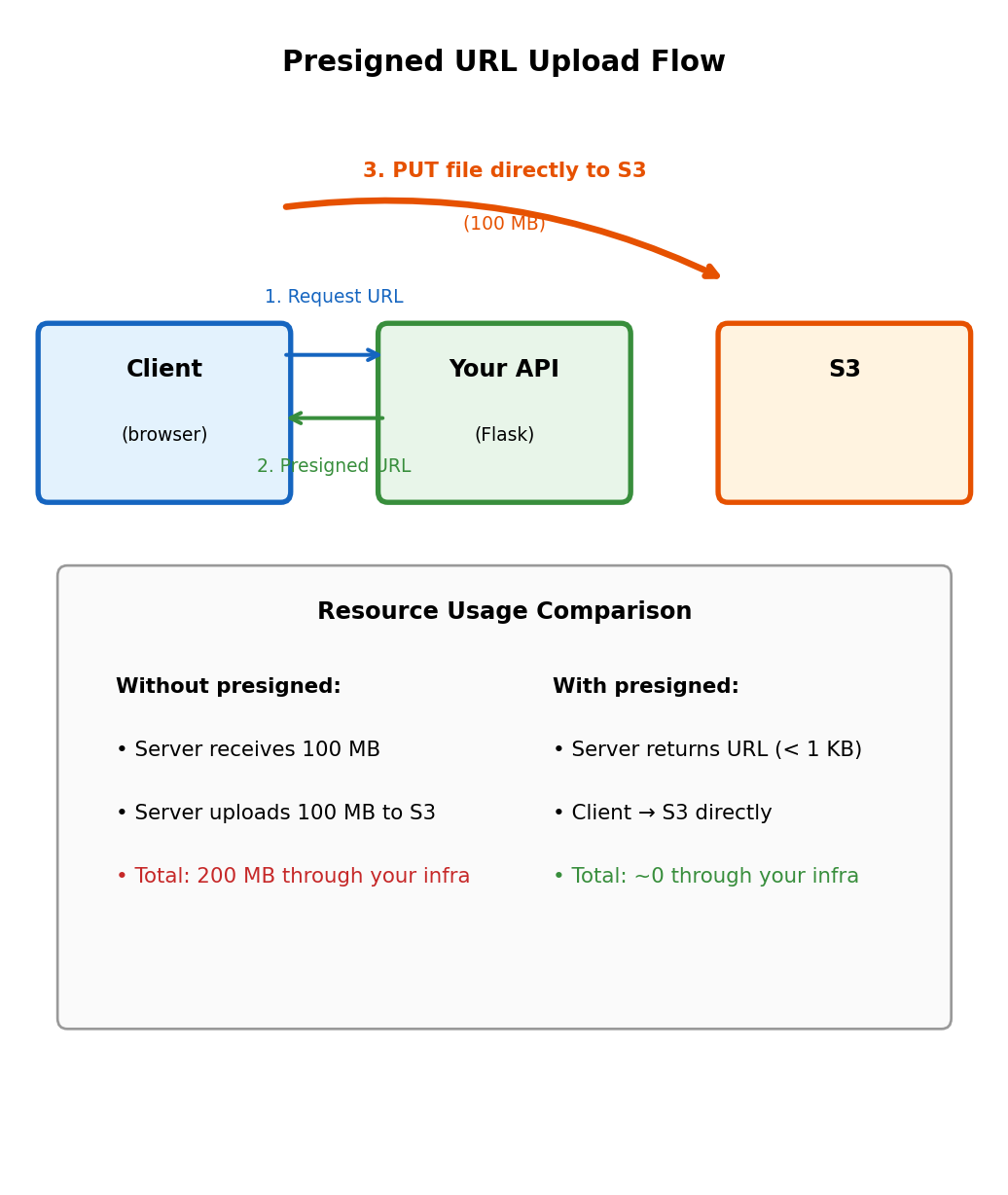
Presigned URLs Enable Direct Client-to-S3 Transfer
Without presigned URLs: All data flows through your server
# Client uploads to your API
@app.route('/upload', methods=['POST'])
def upload():
file = request.files['document']
# File bytes received by your server
# Then uploaded to S3
s3.upload_fileobj(file, 'bucket', f'uploads/{file.filename}')
return {'status': 'uploaded'}500 MB file: Consumes your server’s bandwidth, memory, CPU, and time.
With presigned URLs: Client uploads directly to S3
# Your API generates presigned URL (< 1 ms)
@app.route('/get-upload-url', methods=['POST'])
def get_upload_url():
key = f"uploads/{uuid.uuid4()}/{request.json['filename']}"
url = s3.generate_presigned_url(
'put_object',
Params={'Bucket': 'uploads-bucket', 'Key': key},
ExpiresIn=3600 # URL valid for 1 hour
)
return {'upload_url': url, 'key': key}
# Client uploads directly to S3 using presigned URL
# Your server never handles the file bytesPresigned URL contains embedded authorization:
https://uploads-bucket.s3.amazonaws.com/uploads/abc123/doc.pdf
?X-Amz-Algorithm=AWS4-HMAC-SHA256
&X-Amz-Credential=AKIA.../us-east-1/s3/aws4_request
&X-Amz-Date=20250115T100000Z
&X-Amz-Expires=3600
&X-Amz-Signature=a1b2c3d4...Signature validates: Bucket, key, expiration time. Cannot be modified - S3 verifies signature.
IAM Roles Provide Automatic Credential Management
Credentials embedded in code or environment: Security risk
# Dangerous: Credentials in code
s3 = boto3.client('s3',
aws_access_key_id='AKIAIOSFODNN7EXAMPLE',
aws_secret_access_key='wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY'
)
# Credentials visible in: git history, logs, error traces, process listingIAM role attached to compute resource
# EC2 instance or Lambda with IAM role
import boto3
s3 = boto3.client('s3') # No credentials specified
s3.upload_file('model.pkl', 'bucket', 'key') # Worksboto3 automatically retrieves credentials from instance metadata service. Credentials rotate automatically (typically hourly). No secrets in code, environment variables, or configuration files.
IAM policy controls access:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": "arn:aws:s3:::ml-artifacts/models/*"
}]
}This policy: Allows read/write to models/ prefix in ml-artifacts bucket. Denies access to other prefixes, other buckets, delete operations.
Attach policy to IAM role, attach role to EC2 instance or Lambda function.
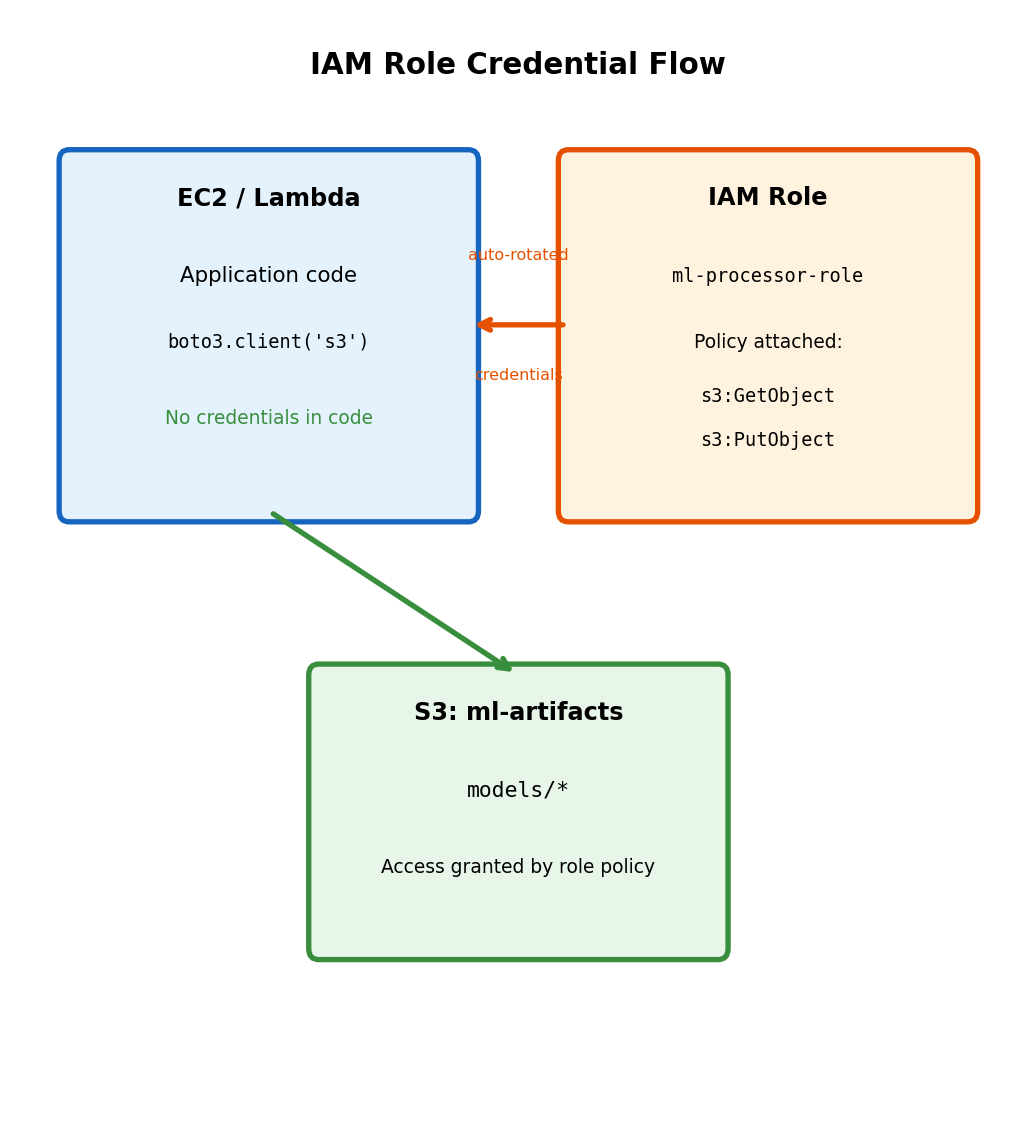
No secrets to manage, rotate, or leak. AWS handles credential lifecycle.
S3 Event Notifications Signal Object Changes
S3 can emit events when objects are created, deleted, or restored
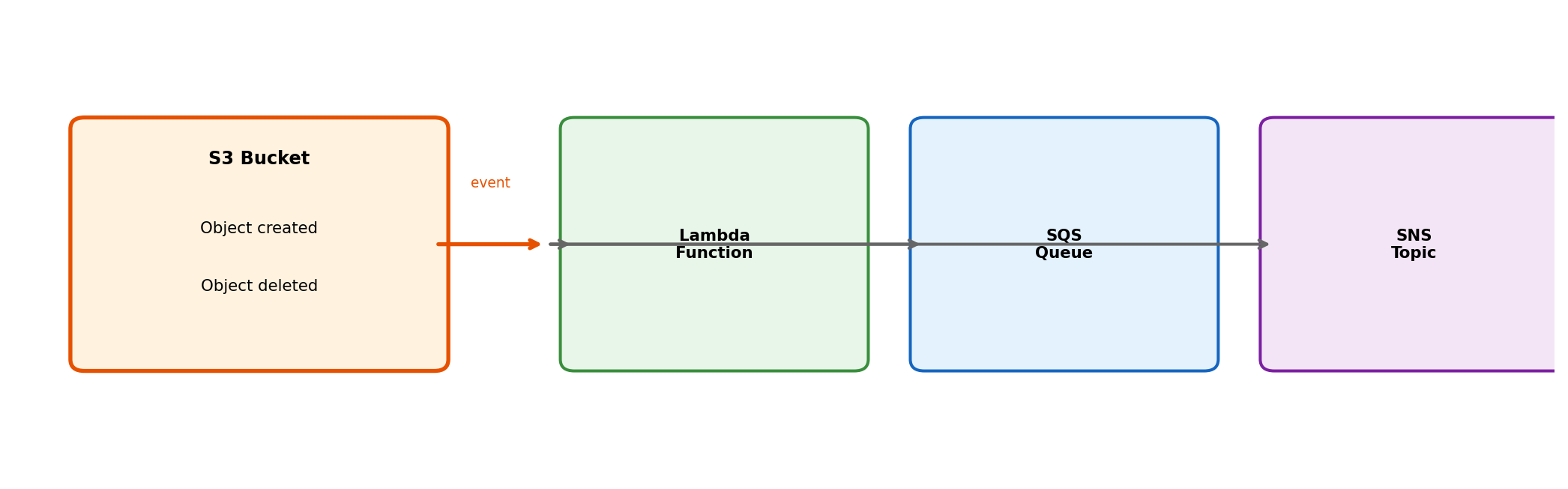
Event configuration on bucket:
- Event types:
s3:ObjectCreated:*,s3:ObjectRemoved:*,s3:ObjectRestore:* - Filter by prefix: Only events for keys starting with
uploads/ - Filter by suffix: Only events for keys ending with
.jpg
Event payload includes:
- Bucket name
- Object key
- Object size
- Event type and timestamp
This enables event-driven architectures: Object uploaded → trigger processing automatically. Integration with Lambda, SQS, and SNS covered in subsequent sections.
S3 Static Website Hosting
Serve static files directly from S3 bucket
Configure bucket for website hosting:
aws s3 website s3://my-site-bucket \
--index-document index.html \
--error-document error.htmlBucket contents:
my-site-bucket/
├── index.html
├── about.html
├── css/styles.css
├── js/app.js
└── images/logo.pngAccess via website endpoint:
http://my-site-bucket.s3-website-us-east-1.amazonaws.com/Browser requests index.html → S3 returns file contents.
Requires public access policy:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::my-site-bucket/*"
}]
}Anyone can read objects. Appropriate for public static content.
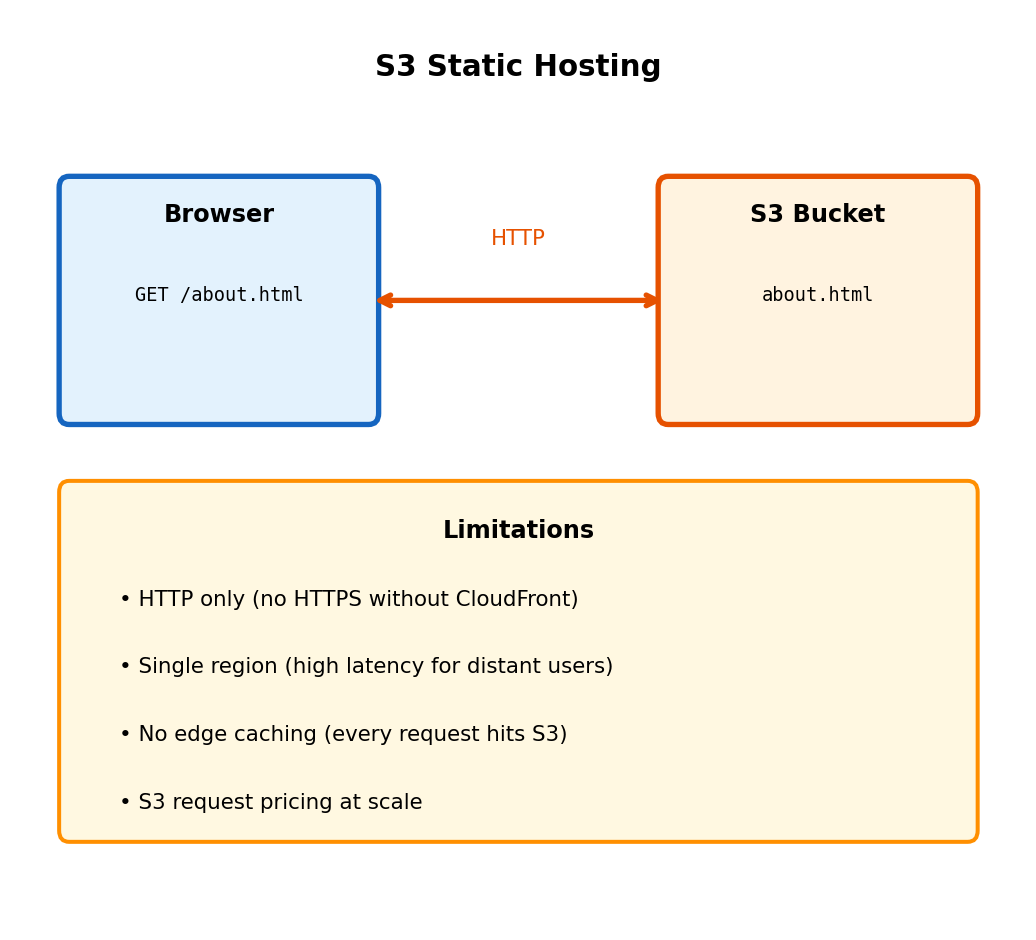
Direct S3 hosting: Development, internal tools. Production typically adds CloudFront for HTTPS, caching, custom domains - covered in integration section.
Choosing Storage Model
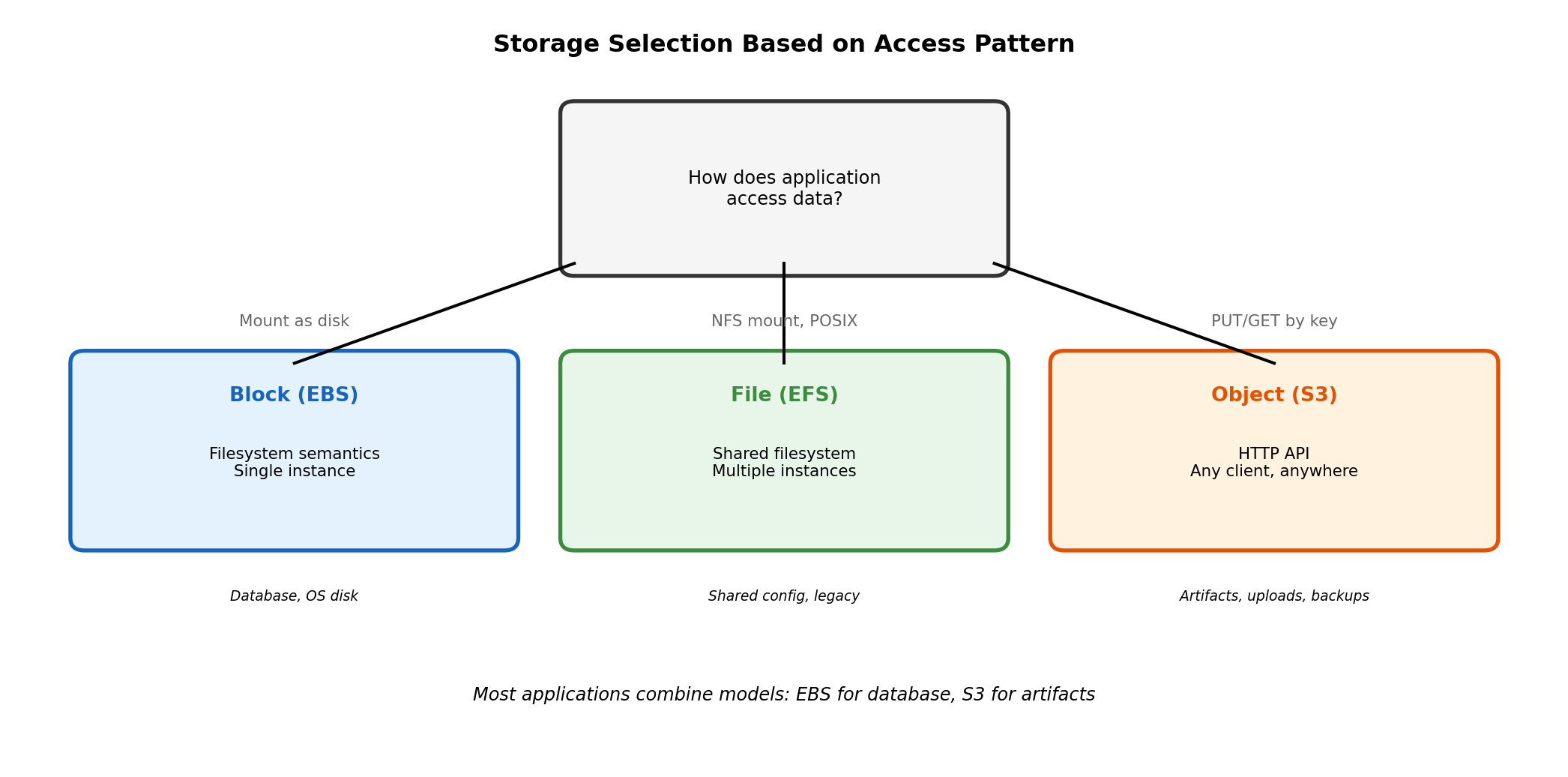
Block when application requires filesystem: Database storage, applications using file paths and standard I/O.
File when multiple instances need shared filesystem: Shared configuration, content management, legacy applications.
Object when HTTP API is acceptable: ML models, user uploads, static assets, backups, any blob storage.
Selection follows from access requirements, not preference.
Server Management in Traditional Deployment
EC2 deployment requires operational decisions:
- Instance type selection (compute/memory balance)
- Operating system installation and updates
- Application runtime setup (Python, Node.js, etc.)
- Security patches and maintenance windows
- Scaling policy configuration
- Health monitoring and alerting
- Load balancer configuration
Your application runs on infrastructure you provision and maintain. The application is always resident - process starts at boot, listens for requests, handles them as they arrive.
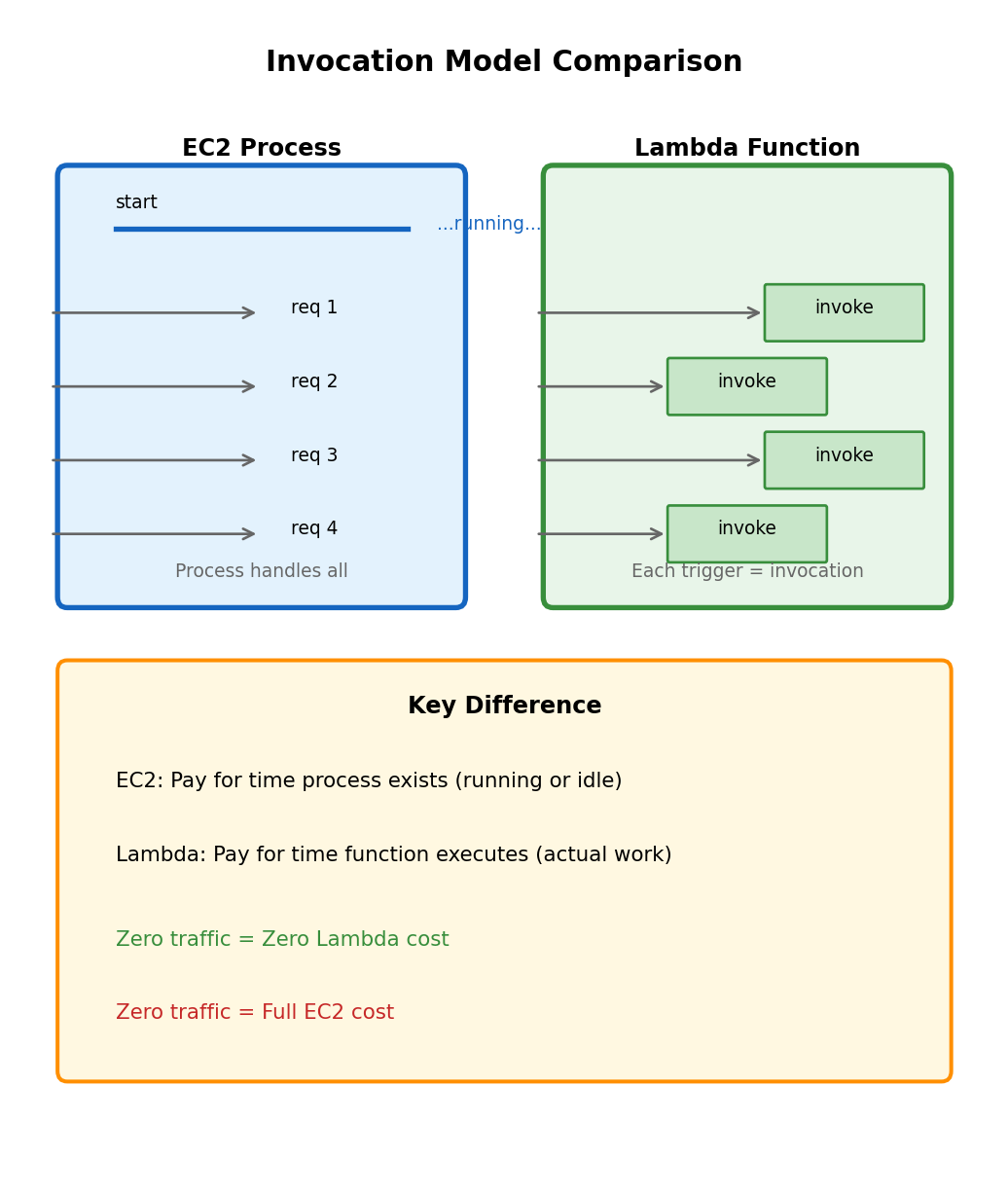
Cost model: Pay for instance hours
Instance runs continuously whether handling 1000 requests/second or 0 requests.
# Check if your Flask app is running
$ ps aux | grep gunicorn
user 12345 0.1 1.2 gunicorn: master [app:app]
user 12346 0.0 0.8 gunicorn: worker [app:app]
user 12347 0.0 0.8 gunicorn: worker [app:app]
# It's running. Waiting for requests. Costing money.The t3.medium running your API costs ~$30/month whether it handles traffic or sits idle.
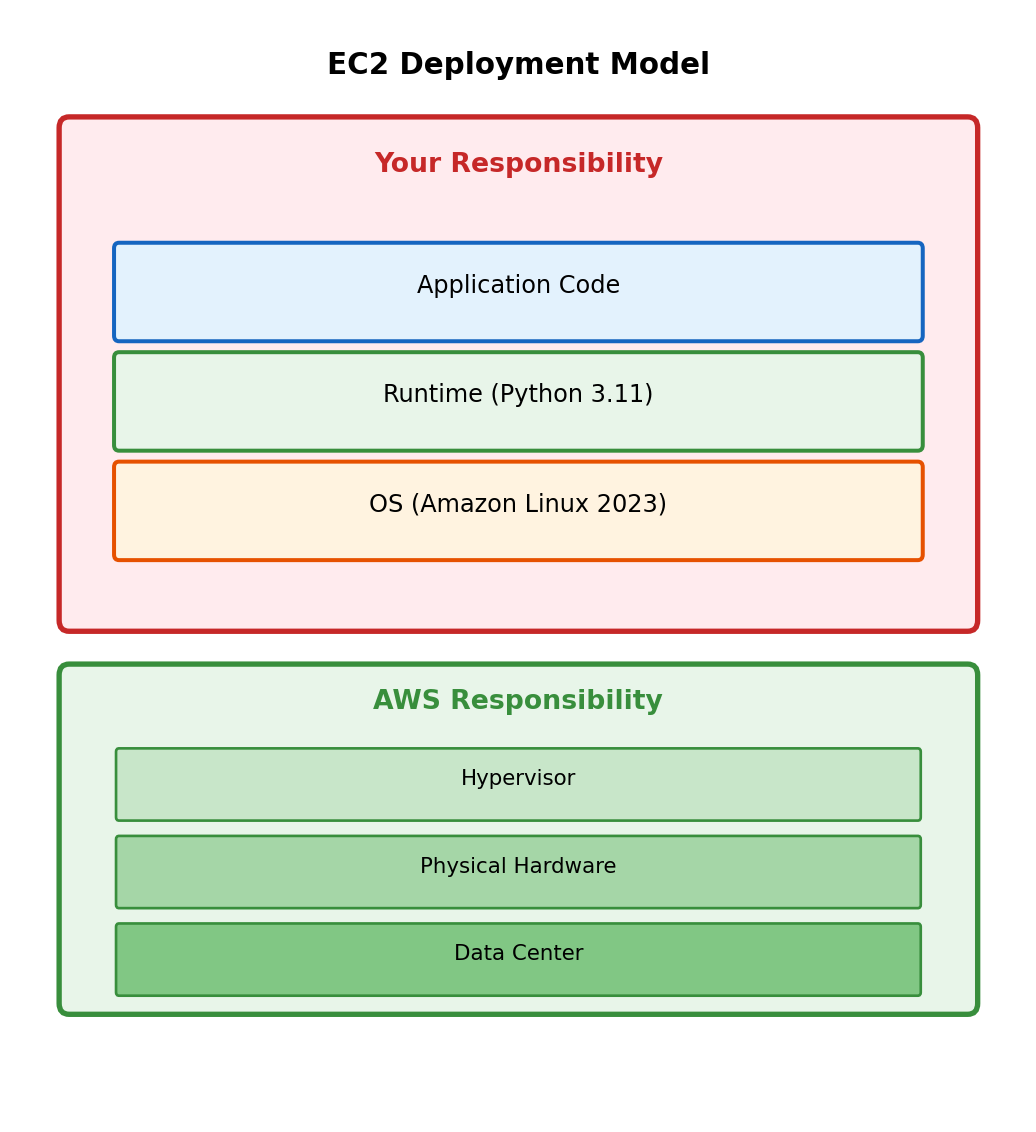
Shifting the Responsibility Boundary
What if AWS managed more of the stack?
Instead of provisioning an EC2 instance where your code runs continuously, you provide only the code. AWS handles:
- Execution environment provisioning
- Runtime installation and patching
- Scaling (including to zero)
- Server allocation and management
The trade-off:
You give up control over the execution environment in exchange for not managing it. No SSH access, no persistent processes, no direct filesystem.
Lambda function: Code as the deployment unit
# handler.py - This IS your entire deployment
def handler(event, context):
"""AWS invokes this function when triggered"""
name = event.get('name', 'World')
return {
'statusCode': 200,
'body': f'Hello, {name}!'
}No Flask, no gunicorn, no server configuration. You deploy this function. AWS runs it when something triggers it.
“Serverless” doesn’t mean no servers - it means servers aren’t your concern.
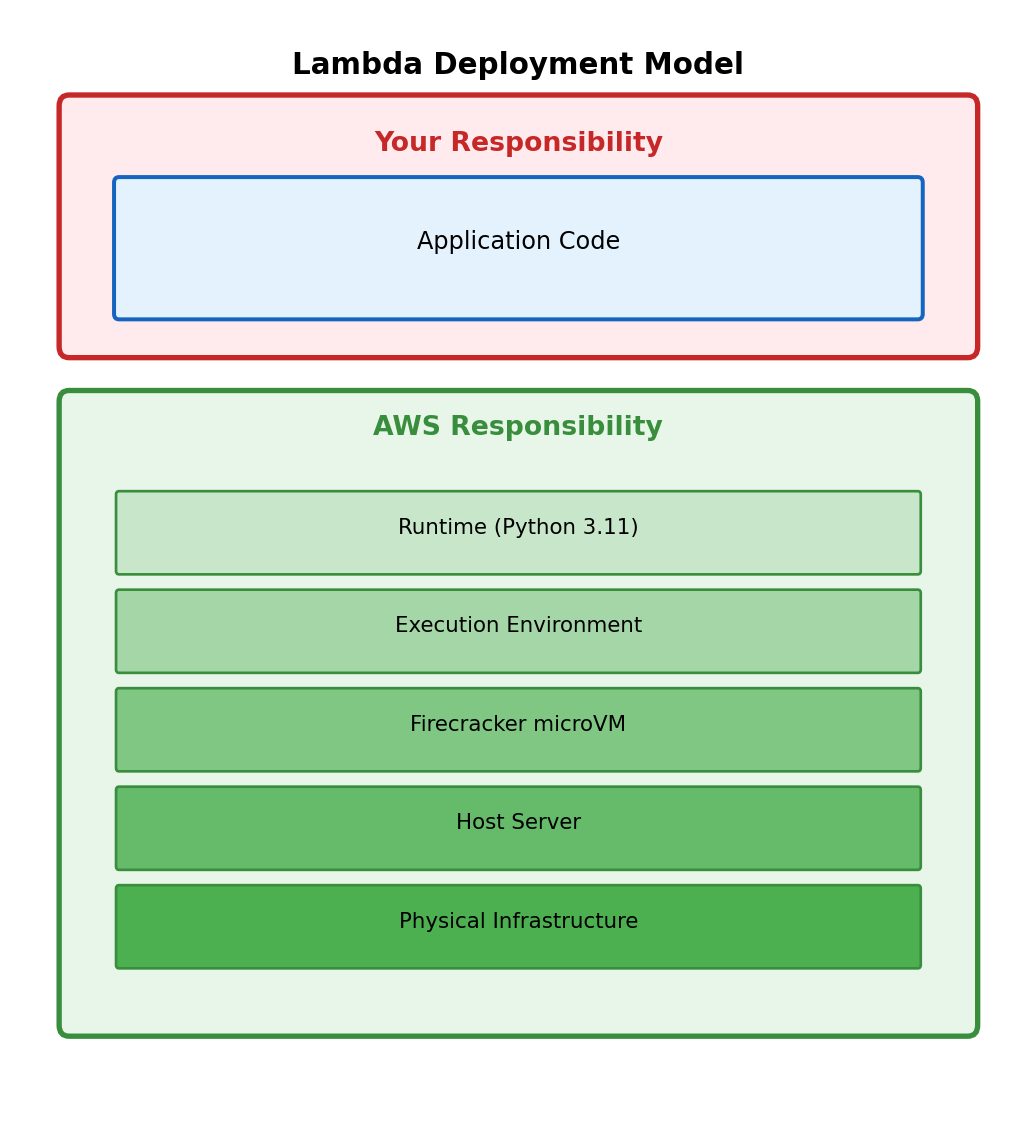
AWS manages runtime, patching, scaling, and infrastructure. You manage code.
Function Invocation vs. Process Lifecycle
EC2: Long-running process
# Flask app - process starts once, handles many requests
app = Flask(__name__)
@app.route('/greet')
def greet():
return f'Hello, {request.args.get("name", "World")}!'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
# Process runs until terminated
# Maintains state between requests
# Keeps connections openThe process initializes once. Each request uses the already-running process.
Lambda: Function invoked per trigger
# Lambda handler - invoked fresh for each trigger
def handler(event, context):
# No persistent process
# No listening socket
# Function runs, returns, done
return {
'statusCode': 200,
'body': f'Hello, {event.get("name", "World")}!'
}Your function is invoked when something triggers it. There’s no “main” loop, no server listening. Lambda is not running your code right now - it will run your code when triggered.
The event parameter contains trigger data:
- HTTP request details (if triggered by API Gateway)
- S3 object information (if triggered by S3 event)
- Message body (if triggered by SQS message)
- Custom JSON (if triggered directly)
What is an Execution Environment?
Lambda functions don’t run directly on bare hardware. AWS creates an execution environment - an isolated container-like sandbox for your code.
Execution environment provides:
- Runtime (Python 3.11, Node.js 20, etc.)
- Your deployed code (handler + dependencies)
- Allocated memory (128 MB - 10 GB, you configure)
- Temporary filesystem (
/tmp, 512 MB - 10 GB) - Environment variables you configure
- AWS SDK for your runtime
Execution environment isolation:
- Each environment isolated from others
- Cannot see or affect other functions
- Cannot see concurrent invocations of same function
# Your handler runs inside the execution environment
def handler(event, context):
# context provides environment information
print(f"Request ID: {context.aws_request_id}")
print(f"Memory limit: {context.memory_limit_in_mb} MB")
print(f"Time remaining: {context.get_remaining_time_in_millis()} ms")
# Do work
return {'statusCode': 200, 'body': 'Done'}context object provides invocation and environment information.
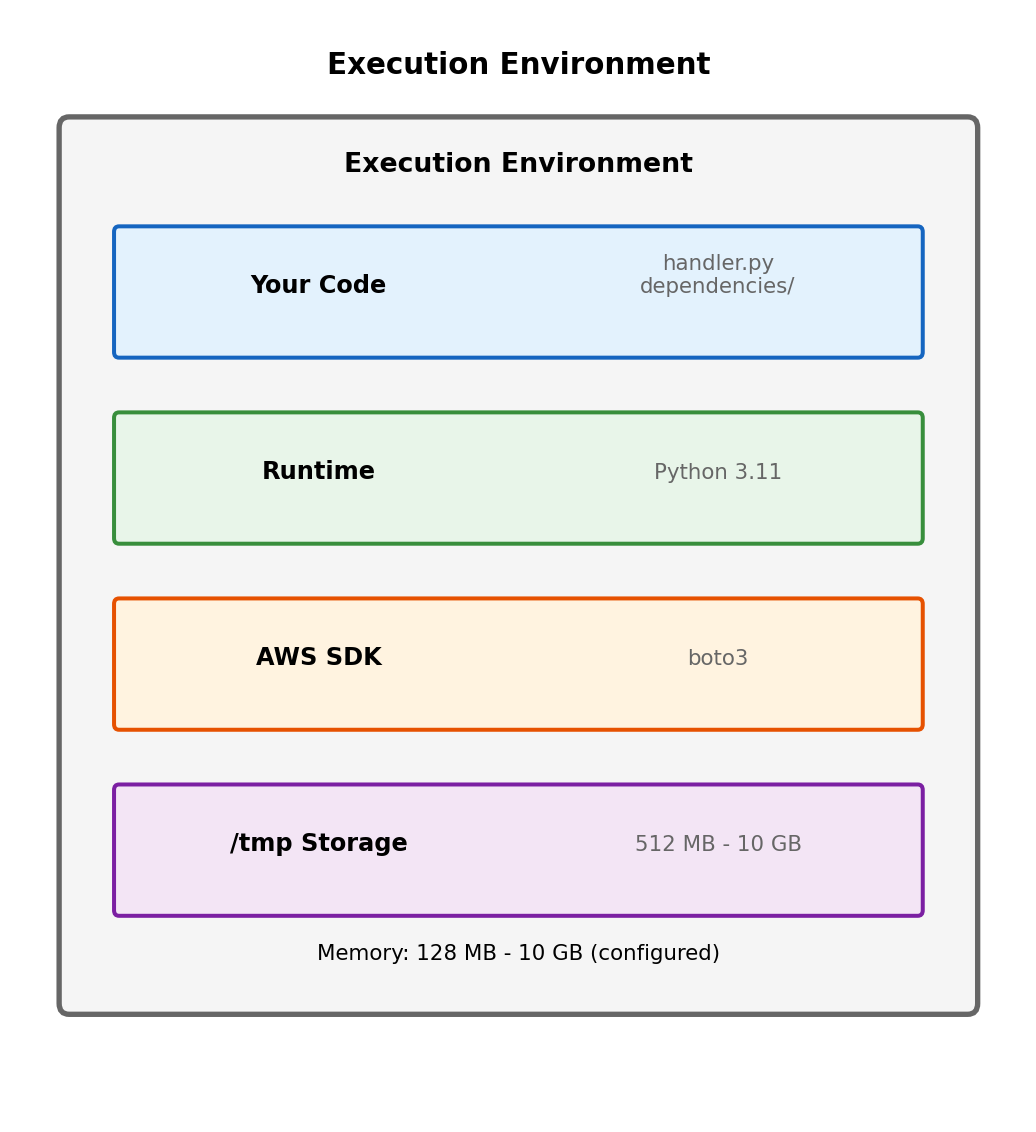
The execution environment is the sandbox where your function runs. You configure its resources; AWS manages its lifecycle.
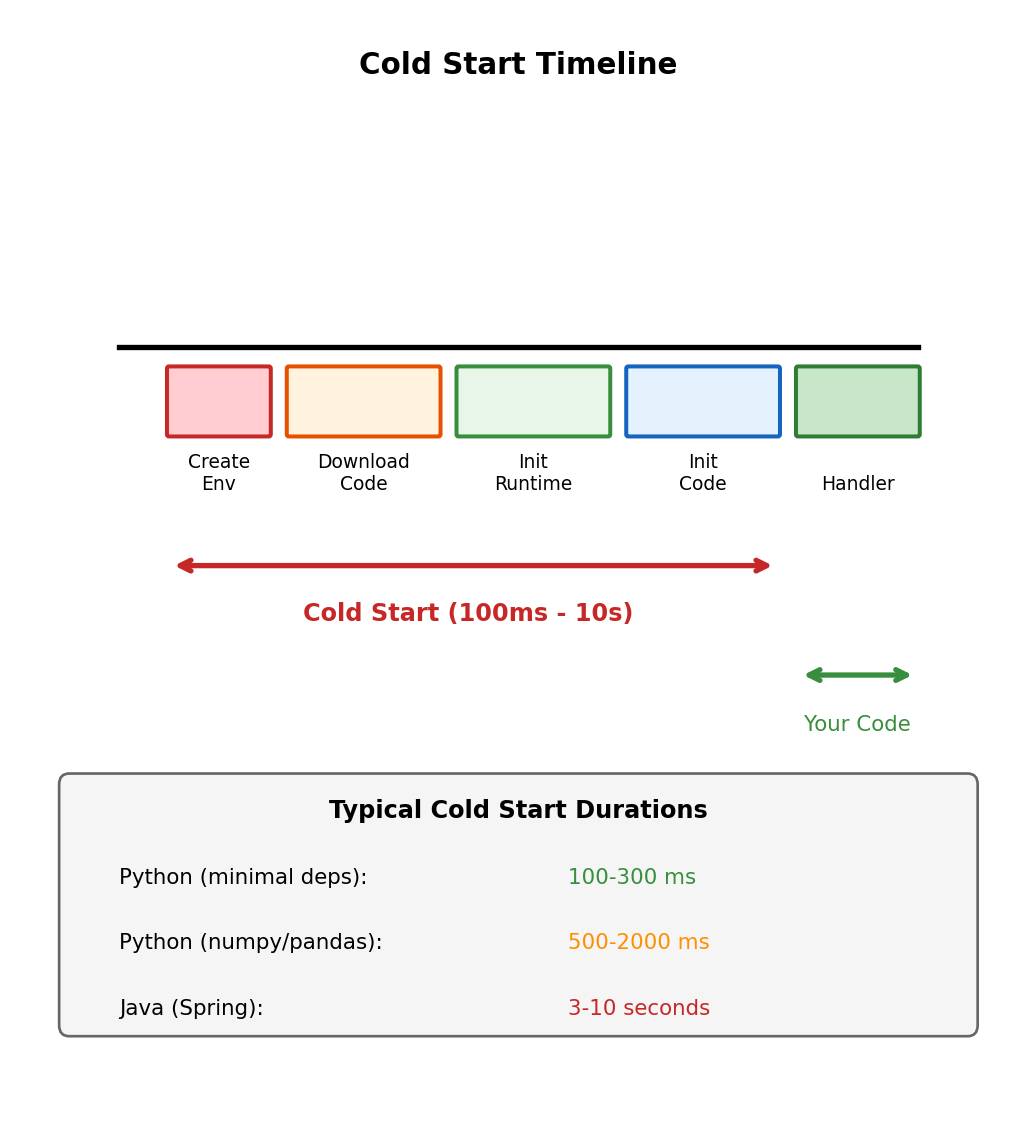
Cold Start: Creating a New Execution Environment
First invocation creates the environment
No suitable execution environment exists → Lambda must create one. This is a cold start.
Cold start phases:
- Environment creation - AWS allocates resources, creates the sandbox
- Code download - Your deployment package downloaded from S3
- Runtime initialization - Python interpreter starts, loads modules
- Handler initialization - Code outside handler function runs
# handler.py
import json
import boto3
import heavy_ml_library # Imported during cold start
# This runs ONCE during cold start, not per invocation
s3_client = boto3.client('s3')
model = heavy_ml_library.load_model('model.pkl')
def handler(event, context):
# This runs on EVERY invocation
result = model.predict(event['data'])
return {'statusCode': 200, 'body': json.dumps(result)}Imports and module-level code execute during initialization. handler function executes on each invocation.
Cold start duration depends on:
- Deployment package size
- Number and size of dependencies
- Initialization code complexity
- Runtime choice (Python, Java, Node.js differ)
- Memory allocation (more memory = faster CPU = faster init)
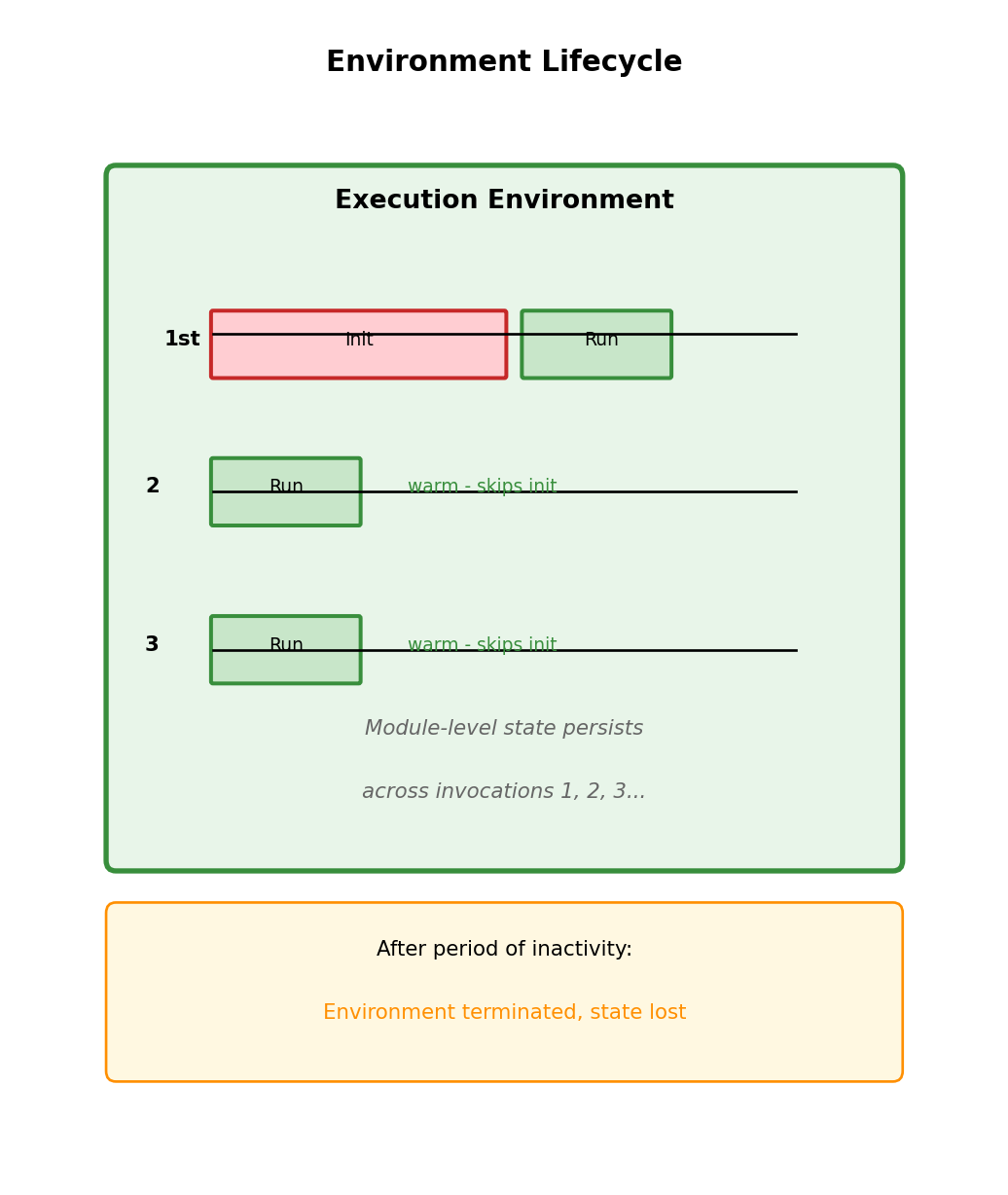
Warm Invocation: Reusing Execution Environments
AWS keeps execution environments alive
After function completes, environment isn’t immediately destroyed. Kept available for subsequent invocations → can be reused.
Warm invocation skips initialization:
Cold: [Create Env][Download][Init Runtime][Init Code][Handler]
Warm: [Handler]Warm invocations go directly to handler - no environment creation, downloads, or initialization.
Environment reuse implications:
# Module-level state persists between invocations
request_count = 0
db_connection = None
def handler(event, context):
global request_count, db_connection
request_count += 1 # Accumulates across warm invocations!
print(f"This environment has handled {request_count} requests")
# Connection reuse - don't recreate on every call
if db_connection is None:
db_connection = create_connection() # Only on cold start
return {'statusCode': 200}Not guaranteed - AWS may terminate environment at any time. In practice, warm environments handle many invocations before termination.
Environment reuse is why:
- Database connection pooling works
- Cached data persists between calls
- Global state accumulates (sometimes unexpectedly)
/tmp Storage: Ephemeral but Persistent Within Environment
Writable filesystem in the execution environment
/tmp directory: 512 MB to 10 GB (configurable). Only writable location - code package is read-only.
import os
import tempfile
def handler(event, context):
# Can write to /tmp
with open('/tmp/cache.json', 'w') as f:
json.dump(event, f)
# Can read it back
with open('/tmp/cache.json', 'r') as f:
data = json.load(f)
# Check space
statvfs = os.statvfs('/tmp')
available_mb = (statvfs.f_frsize * statvfs.f_bavail) / (1024 * 1024)
print(f"Available /tmp space: {available_mb:.1f} MB")
return {'statusCode': 200}Persistence characteristics:
- Persists across warm invocations (same environment)
- Lost when environment terminates
- Not shared between concurrent invocations (separate environments)
# Pattern: Check if cached before downloading
model_path = '/tmp/model.pkl'
if not os.path.exists(model_path):
# Cold start or model not cached
s3.download_file('bucket', 'model.pkl', model_path)
# Now use model_path - either downloaded or from cache
model = load_model(model_path)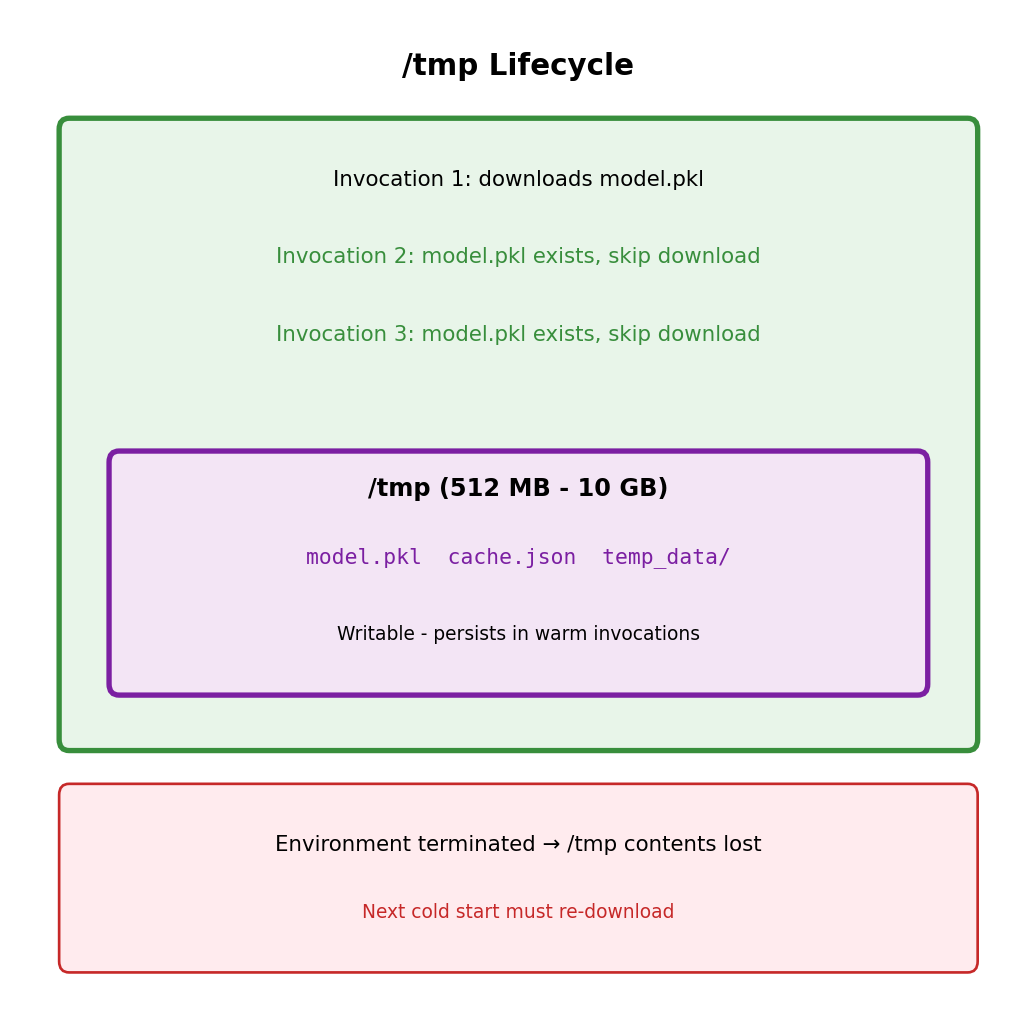
Use for: cached downloads, intermediate processing, temporary data. Don’t rely on for persistence - environment termination not in your control.
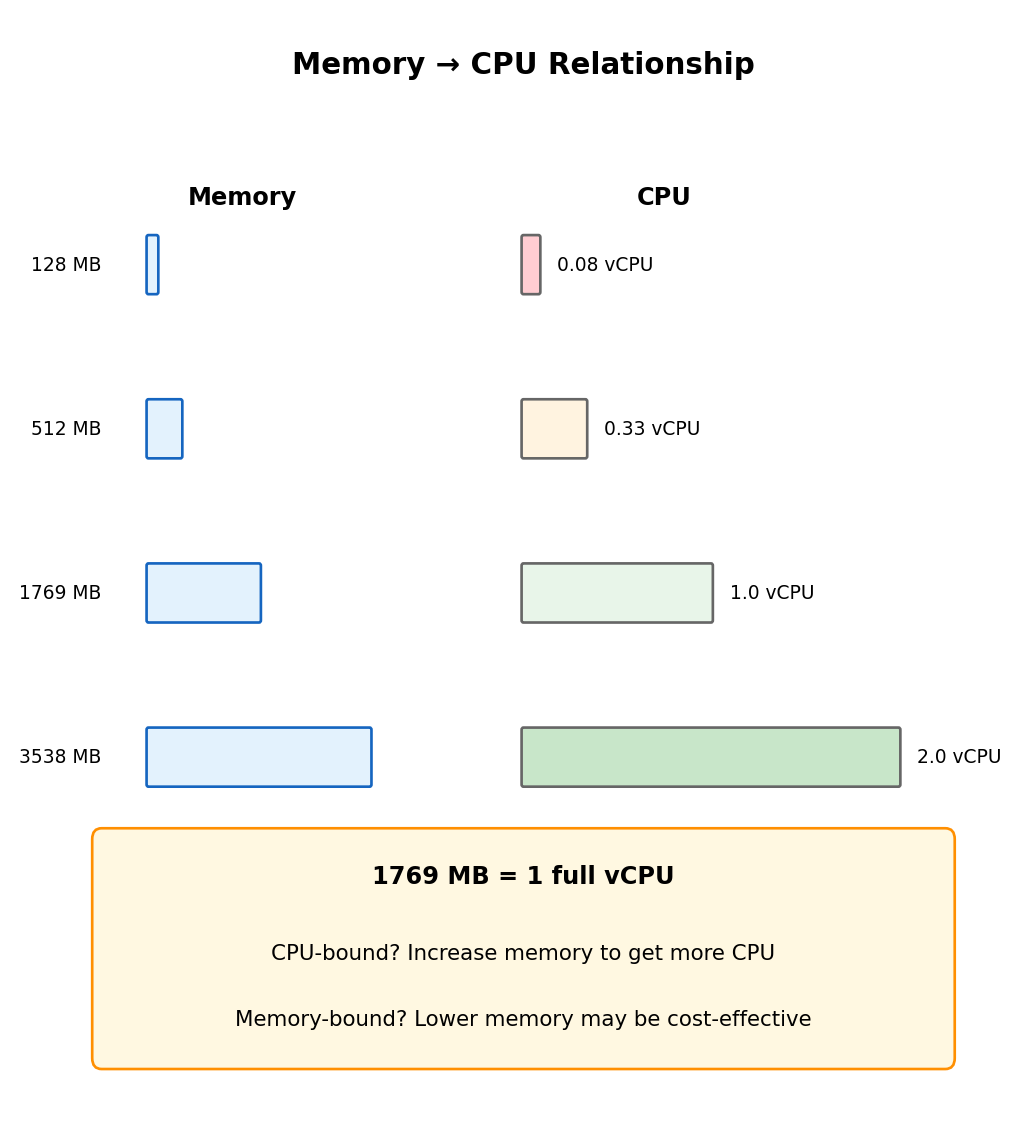
Memory Configuration Determines CPU Allocation
Memory and CPU are proportionally coupled
Configure memory (128 MB to 10 GB). Lambda allocates CPU proportionally - no direct CPU selection.
| Memory | vCPU Equivalent |
|---|---|
| 128 MB | ~0.08 vCPU |
| 512 MB | ~0.33 vCPU |
| 1769 MB | 1 vCPU |
| 3538 MB | 2 vCPU |
| 10240 MB | 6 vCPU |
Implication: CPU-bound work (ML inference, image processing) needs more memory to get more CPU - even if the work doesn’t need the memory.
# If this is slow at 512 MB
def handler(event, context):
# CPU-intensive work
result = expensive_computation(event['data'])
return result
# Increasing to 2048 MB makes it ~4x faster
# Not because we need memory, but because we get more CPUMemory also affects cold start speed:
Higher memory = more CPU = faster initialization. Heavy imports may have faster cold starts at higher memory - potentially reducing total cost despite higher per-ms price.
Timeout: Hard Limit on Execution Duration
Functions have a maximum execution time
Configurable: 1 second to 15 minutes. Function doesn’t complete in time → Lambda terminates it.
def handler(event, context):
# Check remaining time
remaining_ms = context.get_remaining_time_in_millis()
print(f"Time remaining: {remaining_ms} ms")
# Long-running work
for item in event['items']:
if context.get_remaining_time_in_millis() < 5000:
# Less than 5 seconds left - stop gracefully
return {
'statusCode': 200,
'body': 'Partial completion - timeout approaching'
}
process_item(item)
return {'statusCode': 200, 'body': 'Complete'}Timeout termination:
- Function stops immediately (mid-execution)
- No cleanup code runs
- Invocation marked as error
- Any partial work may be lost
Setting appropriate timeouts:
- Too short: unnecessary failures
- Too long: hung functions consume resources, cost money
- Rule of thumb: expected duration + buffer for variability
Typical values: API handlers 10-30s, batch processing up to 15 min. Need longer? Use Step Functions or break into smaller pieces.

Layers: Shared Code Across Functions
Deployment package structure
Lambda code lives in a deployment package - handler plus dependencies:
function.zip
├── handler.py
├── numpy/
├── pandas/
└── sklearn/Multiple functions with same dependencies → each includes them separately.
Layers separate shared dependencies
Layer: ZIP archive with libraries, custom runtimes, or other dependencies. Functions reference layers instead of bundling everything.
function.zip
└── handler.pyml-dependencies-layer.zip
├── numpy/
├── pandas/
└── sklearn/# Function just imports - layer provides the packages
import numpy as np
import pandas as pd
from sklearn import ensemble
def handler(event, context):
# Libraries from layer are available
df = pd.DataFrame(event['data'])
...Layer benefits:
- Smaller function packages (faster deploys)
- Share dependencies across functions
- Update dependencies separately from code
- AWS provides managed layers (e.g., pandas, numpy)
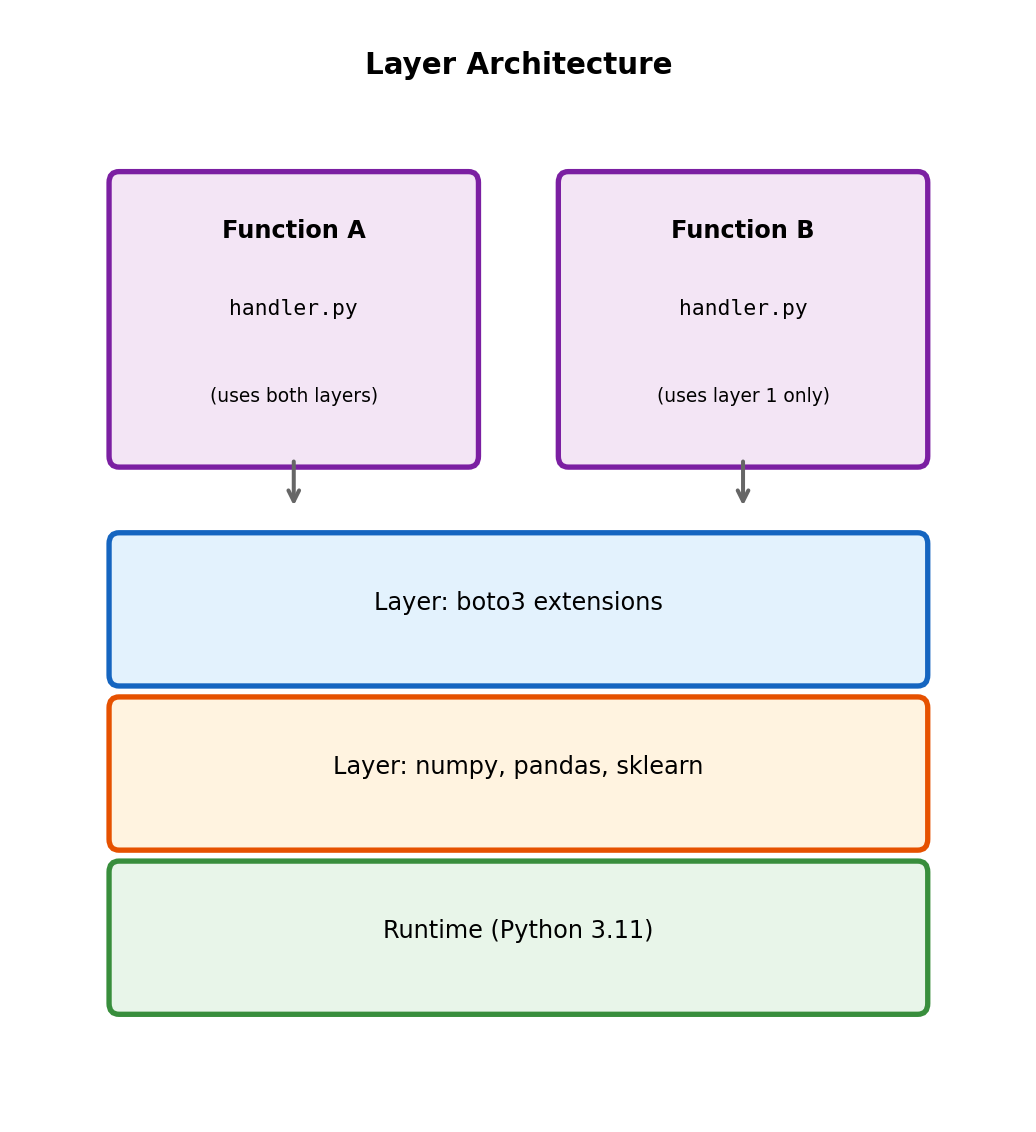
Functions can use up to 5 layers. Total unzipped size (function + layers) limited to 250 MB.
Dependency Size Affects Cold Start
Cold start must download and load your code. More dependencies means:
- Larger download
- More imports to process
- More memory to load modules
Larger packages = longer cold starts
# Minimal dependencies - fast cold start (~200ms)
import json
def handler(event, context):
return {'statusCode': 200, 'body': json.dumps(event)}# Heavy dependencies - slow cold start (~2000ms)
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import tensorflow as tf
def handler(event, context):
# ...Import granularity matters:
# Imports entire sklearn package
from sklearn import *
# Only loads ensemble module
from sklearn.ensemble import RandomForestClassifierLazy imports defer cost to when needed:
def handler(event, context):
if event.get('type') == 'heavy':
import heavy_library # Only import when needed
return heavy_library.process(event)
return simple_response(event)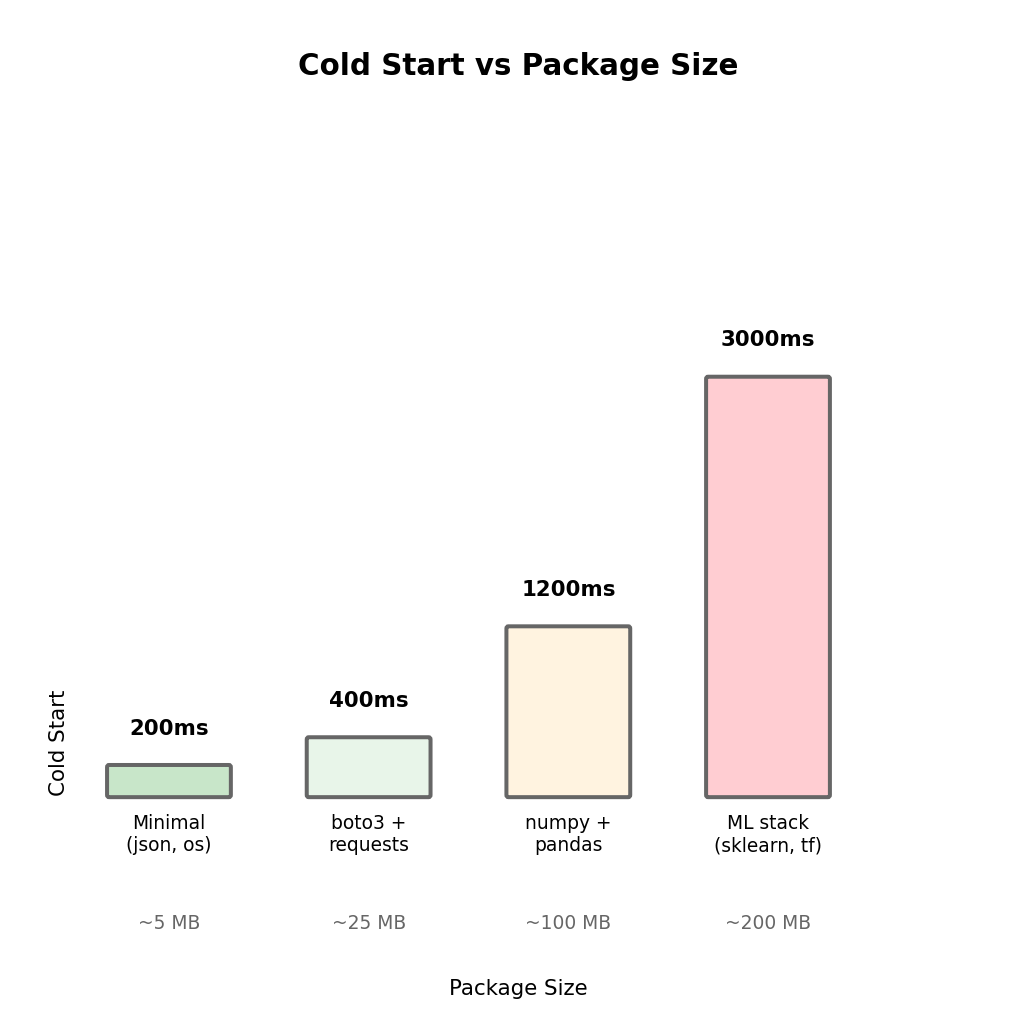
The relationship isn’t linear - some libraries are particularly slow to import (pandas, tensorflow) due to their own initialization logic.
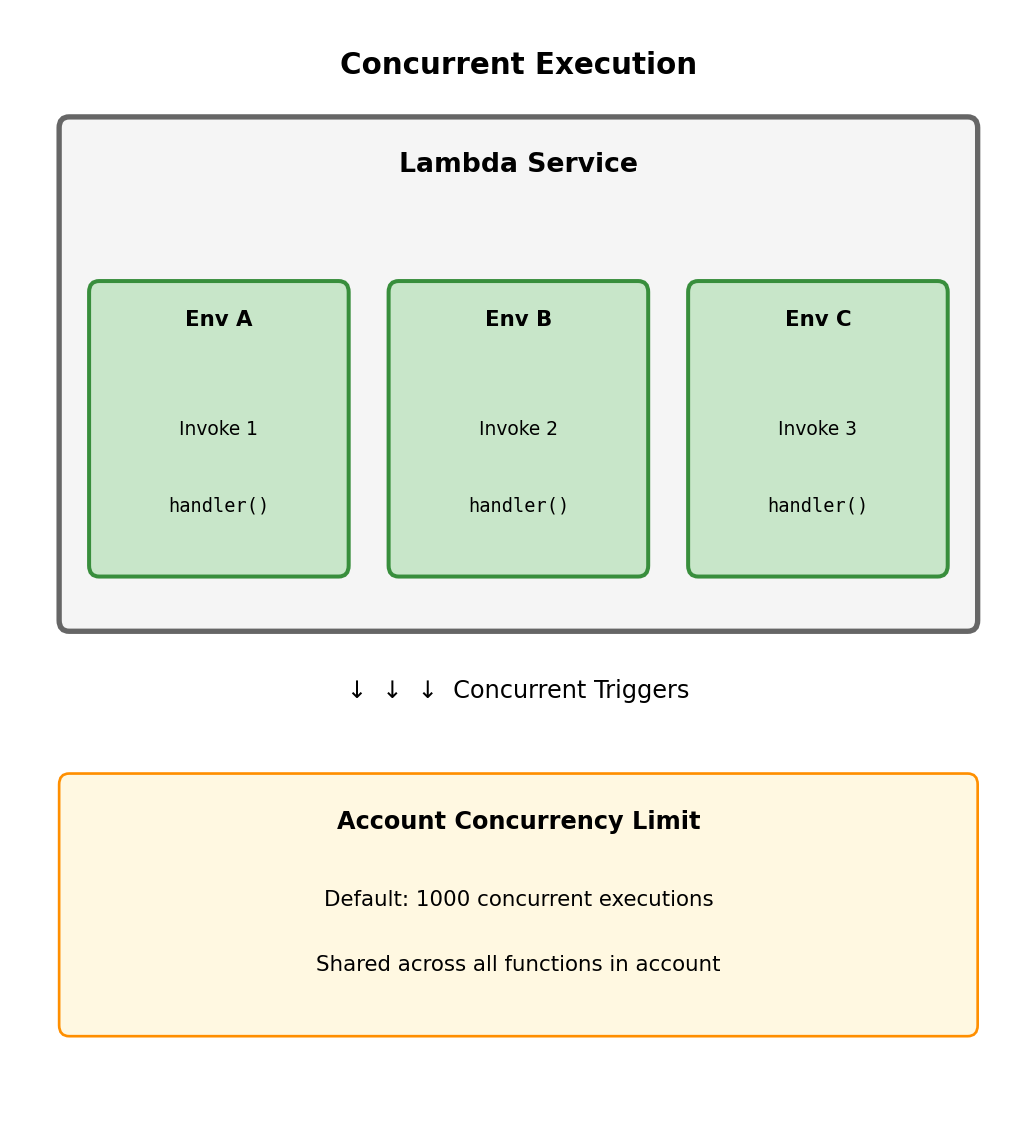
Concurrency: Parallel Execution Environments
When Lambda receives concurrent triggers, it creates additional execution environments. Each concurrent invocation runs in its own isolated environment.
Multiple triggers can arrive simultaneously
Time 0: Trigger 1 arrives → Environment A handles it
Time 10ms: Trigger 2 arrives → Environment B handles it (A still busy)
Time 20ms: Trigger 3 arrives → Environment C handles it
Time 50ms: Trigger 1 completes → Environment A becomes free
Time 60ms: Trigger 4 arrives → Environment A handles it (reused)Concurrency scaling:
- Lambda automatically creates environments as needed
- Scales from 0 to thousands concurrently
- Each new environment incurs cold start
- Default account limit: 1000 concurrent executions
Account-level limit:
All Lambda functions in your AWS account share a concurrency pool. If you have 10 functions and 1000 limit, they collectively can’t exceed 1000 concurrent executions.
# If this function uses 500 concurrency at peak...
def high_traffic_handler(event, context):
...
# ...other functions share the remaining 500
def other_handler(event, context):
...
Lambda Pricing Model
Two pricing components:
- Request charge: Per invocation
- $0.20 per 1 million requests
- Each trigger = one request
- Duration charge: Per GB-second
- $0.0000166667 per GB-second
- GB-second = (memory allocated in GB) × (execution time in seconds)
Example calculation:
Function configuration:
- Memory: 512 MB (0.5 GB)
- Average execution time: 200 ms (0.2 seconds)
- Invocations per month: 1,000,000
Request charges:
1,000,000 requests × $0.20/million = $0.20
Duration charges:
GB-seconds = 0.5 GB × 0.2 sec × 1,000,000 = 100,000 GB-s
100,000 × $0.0000166667 = $1.67
Total monthly cost: $0.20 + $1.67 = $1.87Free tier (per month):
- 1 million requests
- 400,000 GB-seconds
Many low-traffic applications fit entirely in free tier.

Event Sources That Can Trigger Lambda
Lambda functions execute in response to events. These events come from various sources, each delivering data in a specific format to your handler.
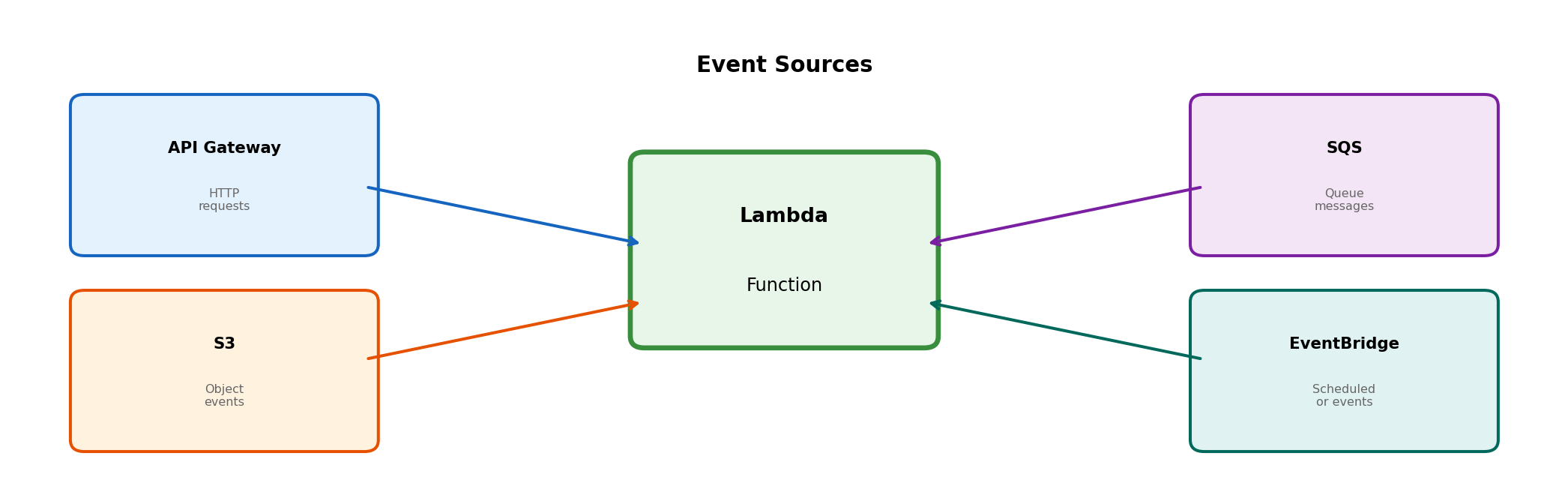
Each source has different characteristics:
| Source | Invocation Type | Use Case |
|---|---|---|
| API Gateway | Synchronous - waits for response | HTTP APIs, webhooks |
| S3 | Asynchronous - fire and forget | File processing, uploads |
| SQS | Poll-based - Lambda pulls messages | Work queues, decoupling |
| EventBridge | Asynchronous | Scheduled tasks, event routing |
The invocation type affects how errors are handled and how your function should respond.
HTTP Requests via API Gateway
API Gateway: HTTP endpoint in front of Lambda
AWS service that accepts HTTP requests, routes to backend services including Lambda. Without it, Lambda has no HTTP endpoint - function exists but no URL to call it.
Integration flow:
- Client sends HTTP request to API Gateway URL
- API Gateway transforms request into Lambda event
- API Gateway invokes Lambda function (synchronous)
- Lambda returns response
- API Gateway transforms response to HTTP response
- Client receives HTTP response
Client → API Gateway → Lambda → Response → Client
(HTTP) (invoke) (return) (HTTP)API Gateway handles:
- HTTPS termination (SSL/TLS)
- Request validation
- Authentication/authorization (optional)
- Rate limiting (optional)
- CORS headers
Lambda handles:
- Business logic
- Response generation

S3 Events: Object-Triggered Invocation
S3 can trigger Lambda on object changes
Configure bucket to emit events on object create/delete/modify. Lambda subscribes to these events.
Common trigger patterns:
s3:ObjectCreated:*- Any object creation (PUT, POST, Copy)s3:ObjectRemoved:*- Any object deletions3:ObjectCreated:Put- Specifically PUT operations
Event configuration can filter by prefix/suffix:
Trigger: s3:ObjectCreated:*
Prefix: uploads/
Suffix: .jpg
Only triggers for: uploads/*.jpg
Does not trigger for: uploads/doc.pdf or images/photo.jpgInvocation is asynchronous:
S3 emits event and continues - doesn’t wait for Lambda. If Lambda fails, S3 doesn’t know or retry. Lambda service handles retries (twice by default).
Use cases:
- Image uploaded → generate thumbnails
- CSV uploaded → process and load to database
- Log file uploaded → parse and index
- Backup file uploaded → validate and catalog

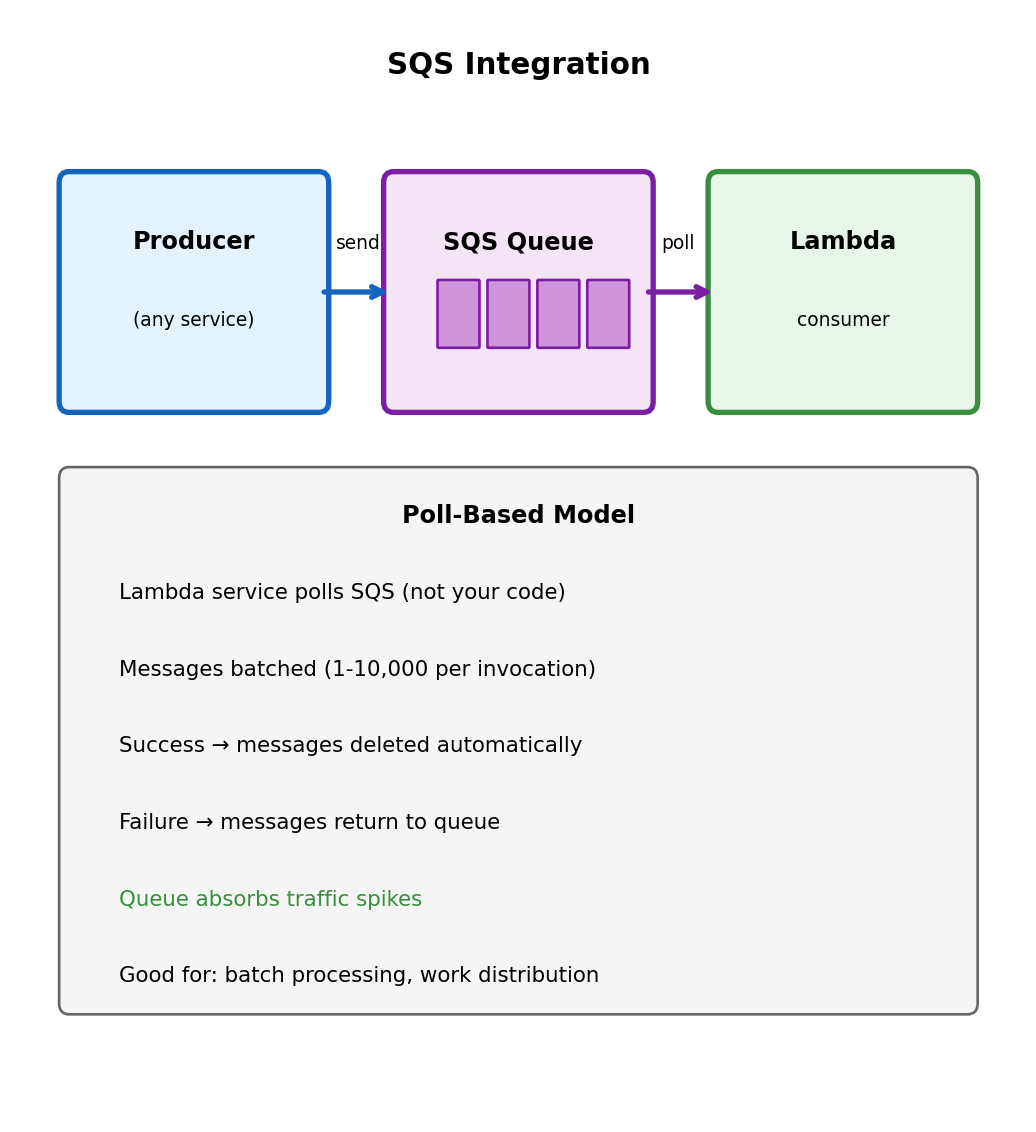
SQS: Poll-Based Invocation
SQS (Simple Queue Service) decouples producers and consumers
Messages placed in queue. Lambda polls and processes. Different from API Gateway (synchronous push) and S3 (asynchronous push).
Why queue-based processing?
- Decoupling: Producer doesn’t need to know about consumer
- Buffering: Queue absorbs traffic spikes
- Retry: Failed messages return to queue
- Rate control: Control how fast Lambda processes
Lambda polls SQS (you don’t):
Lambda service manages polling. Messages available → invokes your function with a batch.
def handler(event, context):
# event['Records'] contains batch of messages
for record in event['Records']:
body = record['body'] # Message content
# Process message
data = json.loads(body)
process_item(data)
# Successful return = messages deleted from queue
# Exception = messages return to queue for retryBatch processing:
Multiple messages per invocation (configurable 1-10,000). Efficient for high-volume queues - one cold start handles many messages.
Lambda in System Architecture
Lambda functions rarely exist in isolation - they connect to other services to form complete systems.
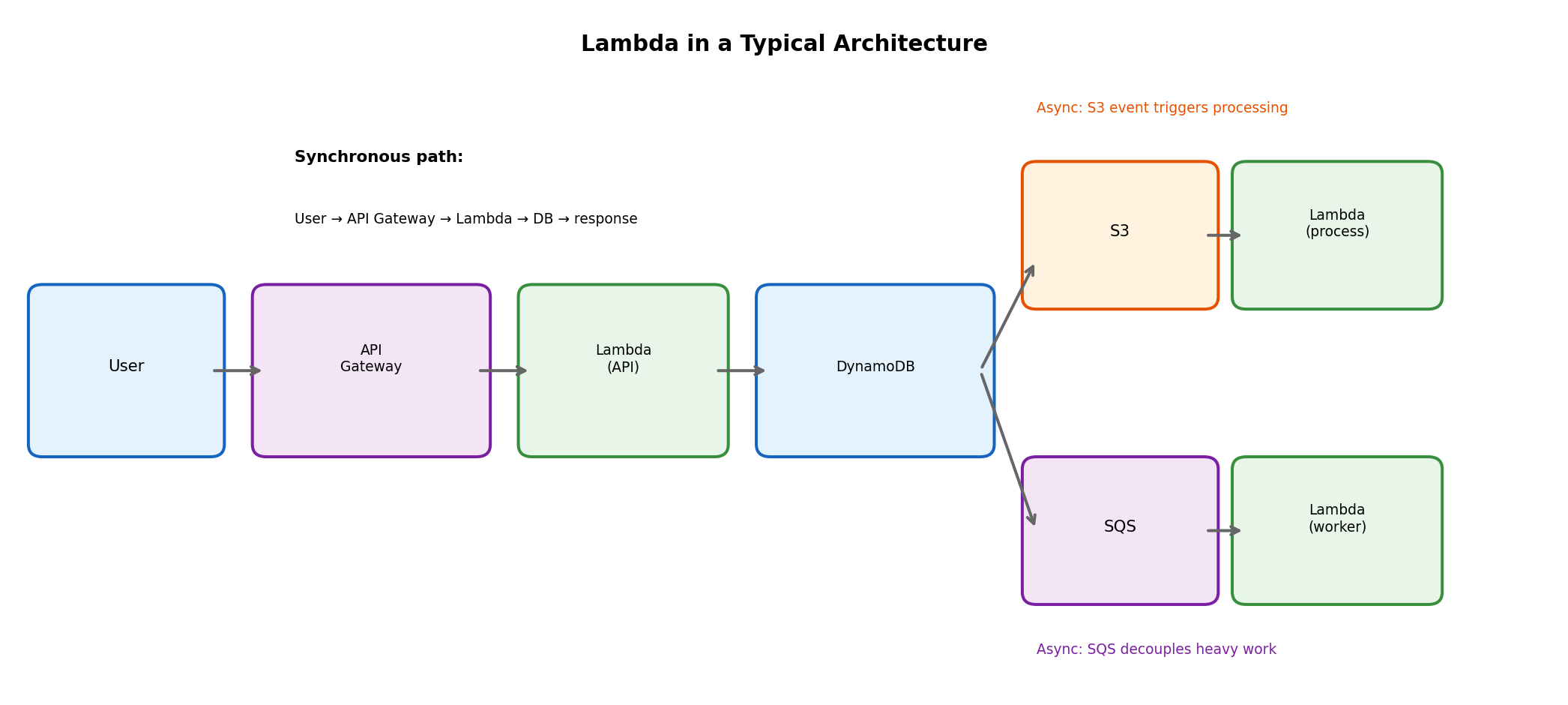
Common integration patterns:
- API Gateway → Lambda → DynamoDB: Synchronous API handling
- S3 → Lambda: Trigger processing when files arrive
- SQS → Lambda: Queue-based work processing
- EventBridge → Lambda: Scheduled tasks, event routing
- Lambda → SQS/SNS: Decouple downstream processing
Each function small and focused. Complex workflows: multiple functions with services between them.
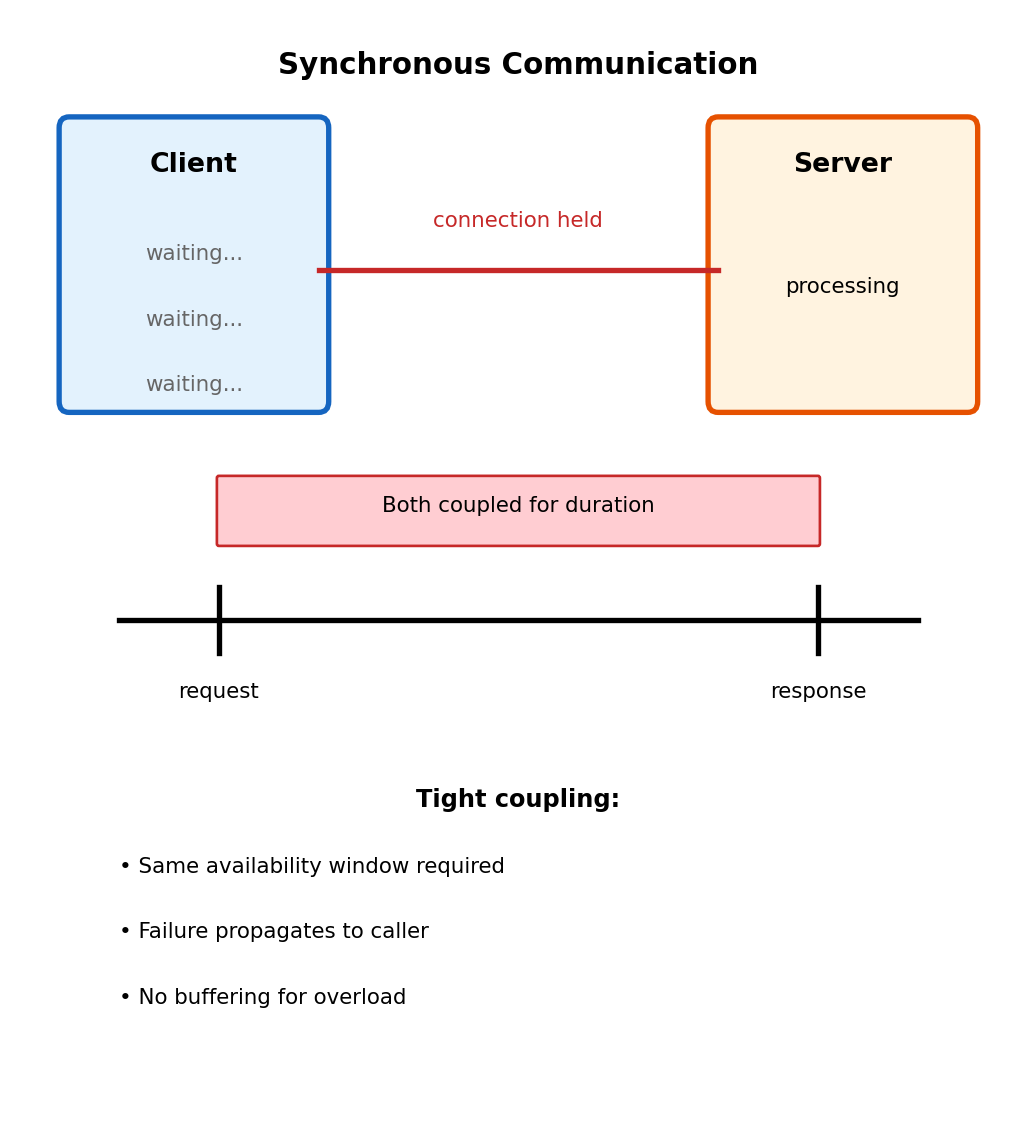
Synchronous Communication: Tight Coupling
Direct call model
def handle_request(request):
order = parse_order(request)
result = process_order(order) # 30 seconds
return resultHTTP connection held entire 30 seconds.
Coupling consequences:
- Client blocks until completion
- Server crash mid-processing → work lost
- Traffic spike beyond capacity → requests rejected
- Both parties must be available simultaneously
When synchronous makes sense:
- User actively waiting (login, search)
- Result needed to proceed
- Processing is fast (sub-second)
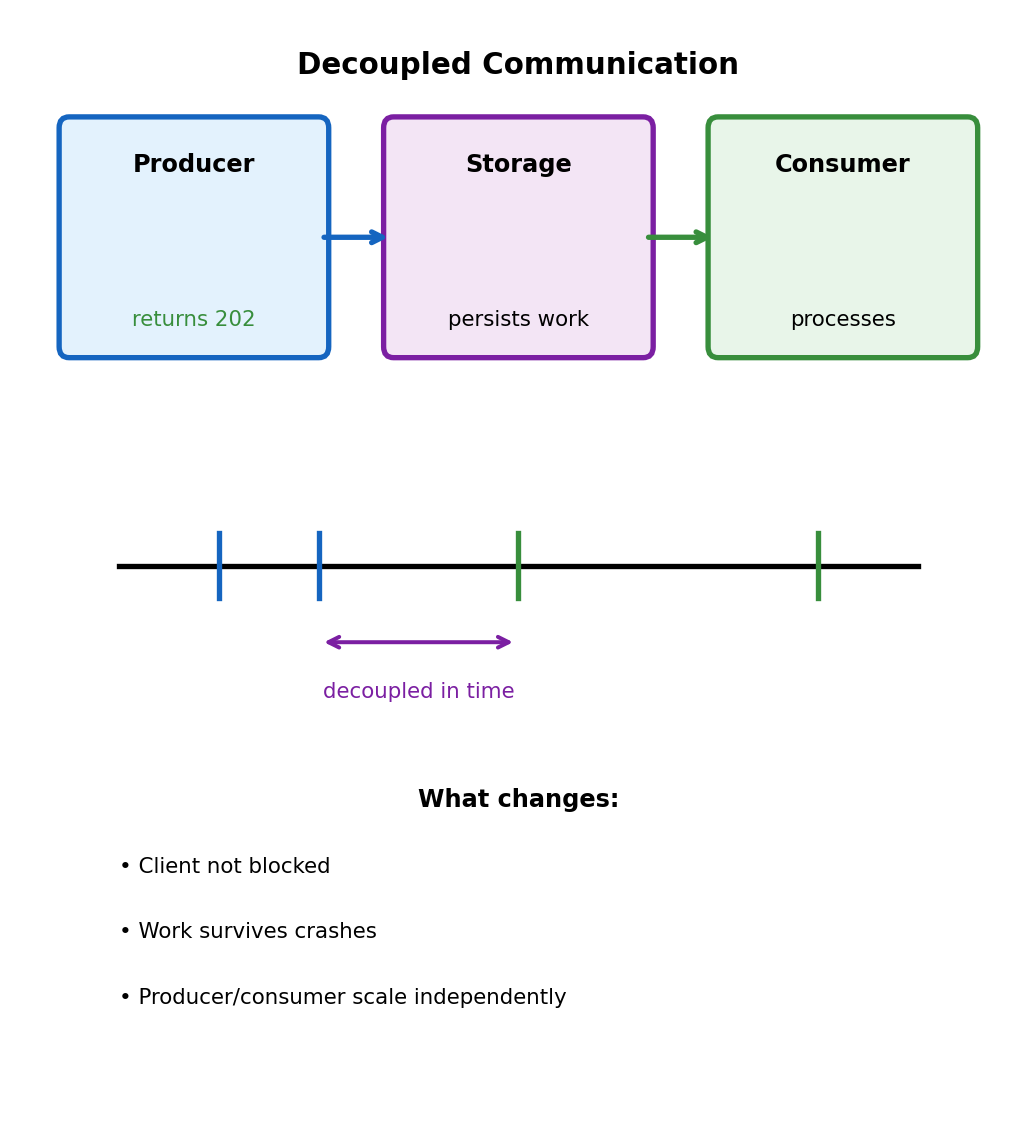
Decoupling via Intermediate Storage
Instead of A → B directly: A → Storage → B
# Producer: accept and acknowledge
def handle_request(request):
job_id = str(uuid.uuid4())
store_job(job_id, request.data)
return {'job_id': job_id, 'status': 'accepted'}, 202
# Consumer: process from storage (separate process)
def process_pending_jobs():
while True:
job = get_next_job()
if job:
result = do_processing(job)
save_result(job.id, result)
mark_complete(job.id)HTTP 202 (Accepted) vs 200 (OK):
- 202 = “accepted your request”
- 200 = “completed your request”
Client checks back later or receives callback.
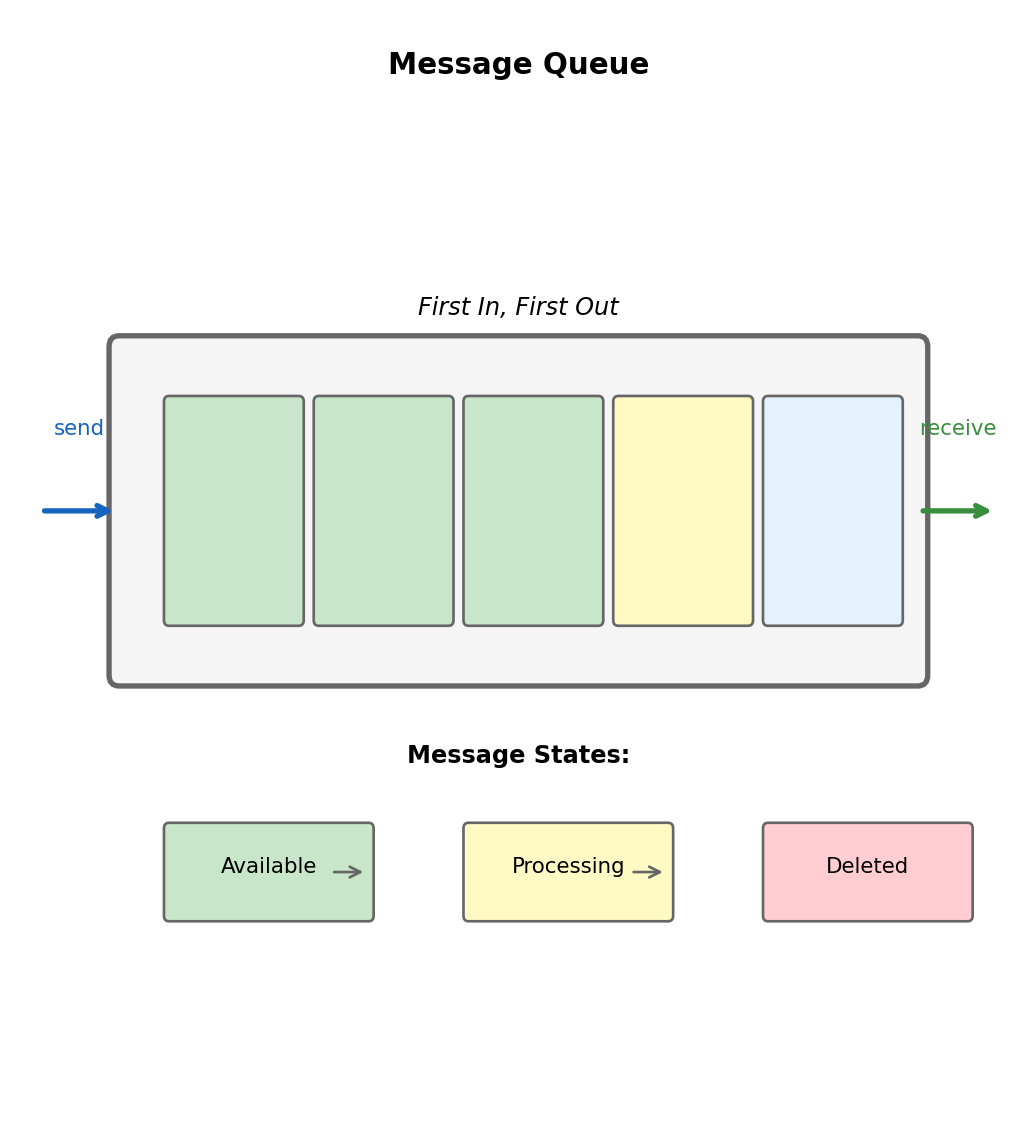
The Message Queue Abstraction
Three fundamental operations
Producer Queue Consumer
| | |
|--- send(msg) ------->| |
| | |
| |<---- receive() -------|
| | |
| | [processing...] |
| | |
| |<---- delete() --------|Send: Add message, returns when durably stored
Receive: Get next message, becomes temporarily invisible
Delete: Confirm complete, permanently removed
Key insight: Message not removed on receive - removed on explicit delete. Enables recovery if consumer fails mid-processing.
Visibility Timeout
What if consumer receives message then crashes before delete?
Mechanism
On receive → message invisible for configurable period
t=0 Consumer A receives
Message invisible (30s timeout starts)
t=15 Consumer A still processing
Message still invisible
t=35 Timeout expired, no delete
Message visible again
t=36 Consumer B receives
Retry beginsTimeout too short: Message reappears while still being processed → duplicate work
Timeout too long: Failed processing waits unnecessarily before retry
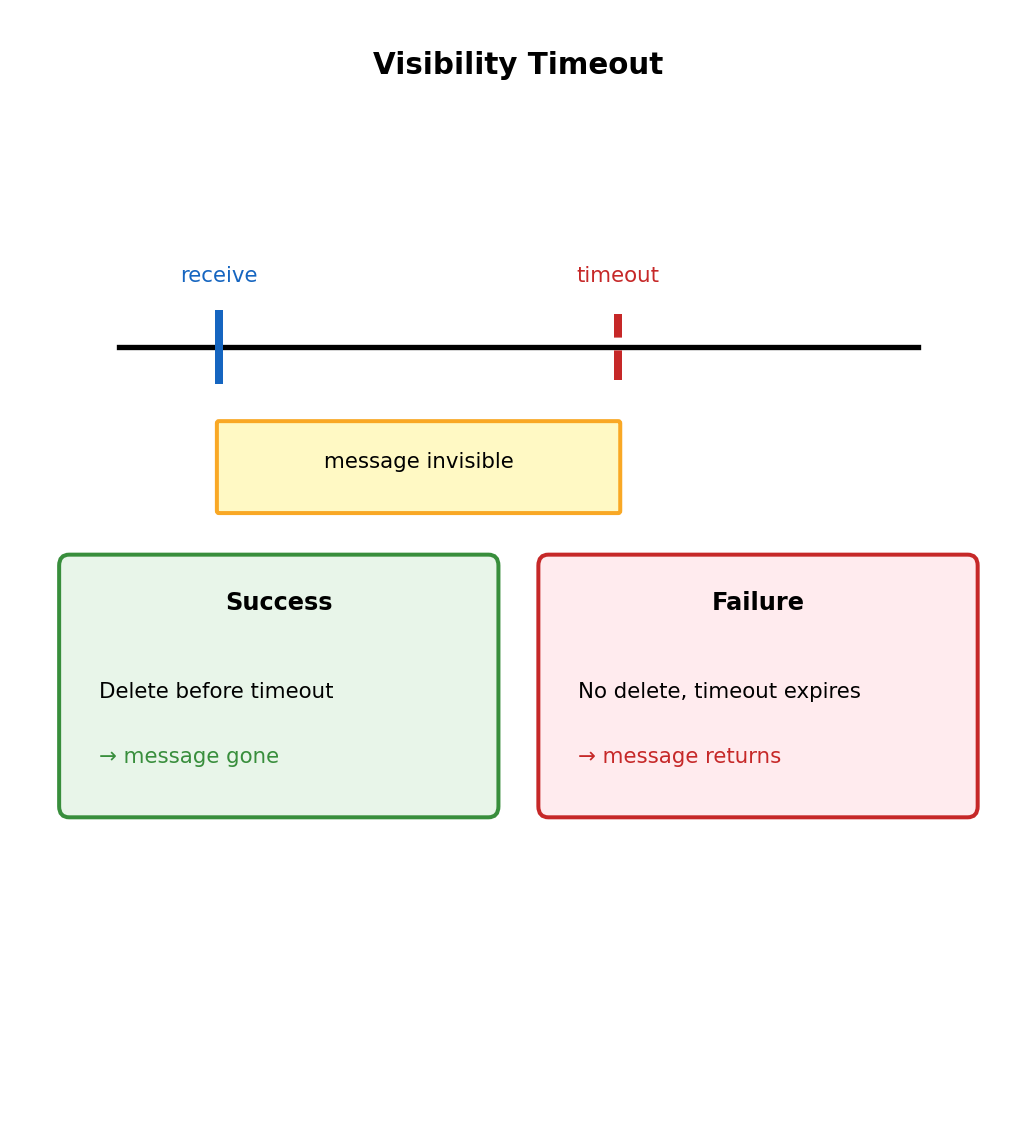
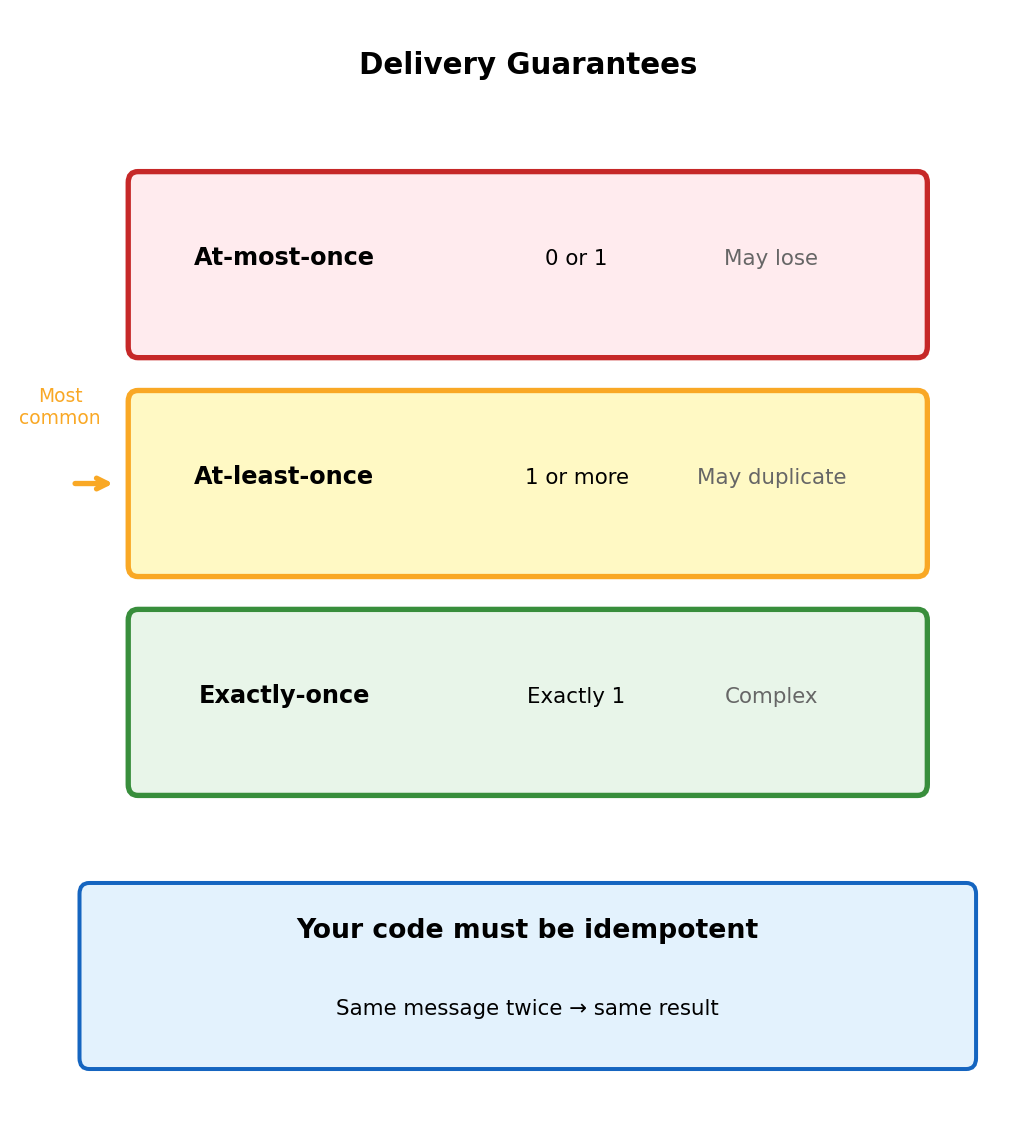
At-Least-Once Delivery
Most queues guarantee: message will be delivered, but might be delivered more than once.
How duplicates occur
1. Consumer receives message
2. Processes successfully (30 sec)
3. Sends delete request
4. Network hiccup - delete lost
5. Queue never receives delete
6. Visibility timeout expires
7. Message visible again
8. Another consumer receives
9. Processed twiceConsumer did everything right. Network unreliability caused duplicate.
Not a bug - fundamental trade-off
Exactly-once requires distributed transactions. Complex, expensive. At-least-once is practical choice.
Implication: Your code must handle duplicates.
Dead Letter Queues
Some messages can never succeed. Invalid data, deleted resources, bugs.
Poison message problem
Message with malformed JSON arrives
Consumer 1: parse fails, crash
Message returns to queue
Consumer 2: parse fails, crash
Message returns to queue
Consumer 3: parse fails, crash
...forever...Queue keeps delivering, consumers keep failing.
Solution: Dead letter queue (DLQ)
After N failed attempts → move to separate queue
- Isolates problem messages
- Healthy messages continue processing
- DLQ = holding area for investigation

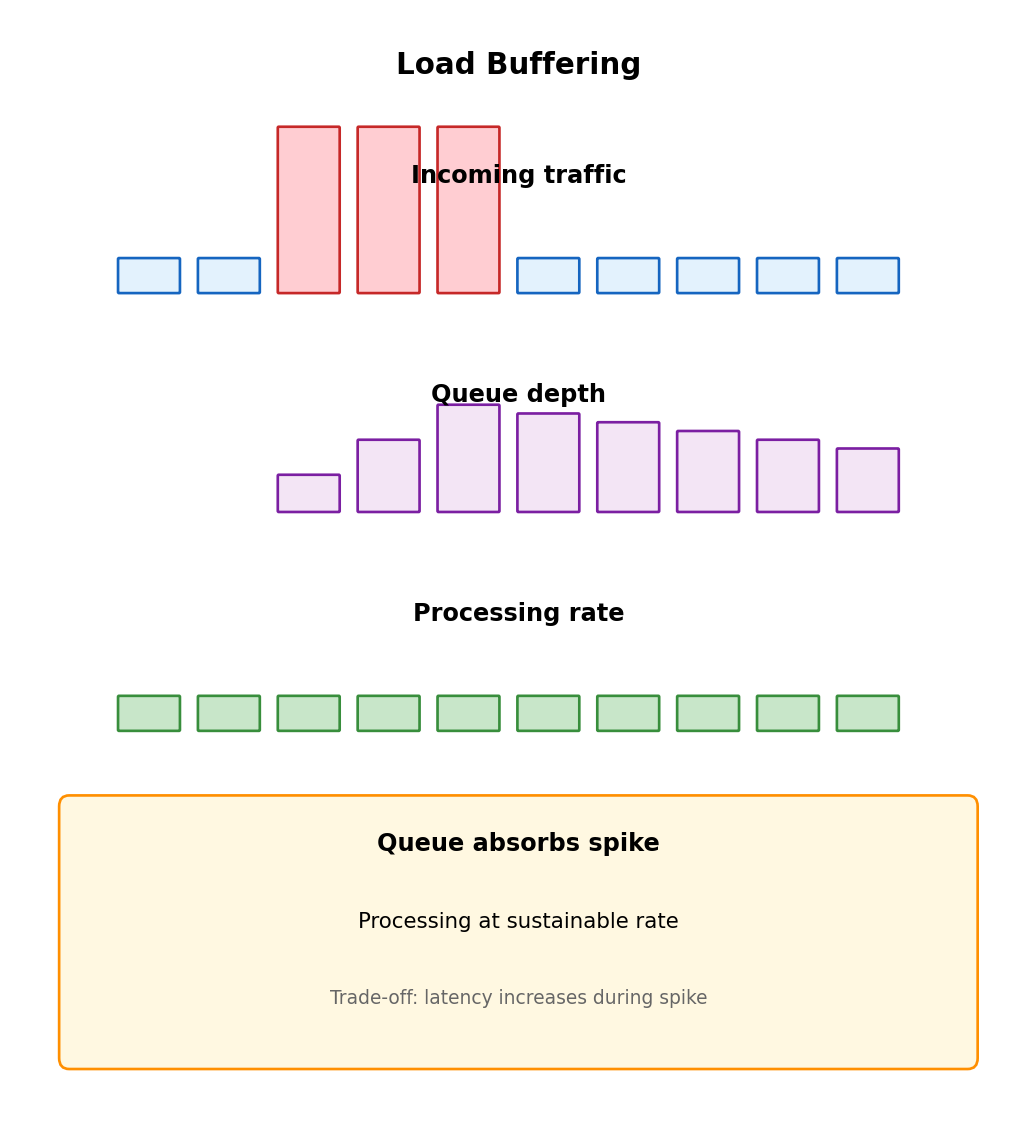
Load Buffering
Queues absorb traffic spikes that exceed processing capacity.
Synchronous under spike
Requests arrive faster than processing capacity:
- Excess requests timeout or rejected
- HTTP 503 Service Unavailable
- Cascading failures as servers overload
Asynchronous under spike
Time Arrivals Queue Processing
00:00 100/sec 0 100/sec
00:01 500/sec 400 100/sec ← spike
00:02 500/sec 800 100/sec
00:03 100/sec 700 100/sec ← spike ends
00:04 100/sec 600 100/sec
...
00:10 100/sec 0 100/sec ← drained- All requests accepted
- Processing rate constant
- Spike absorbed into queue depth
- Gradually drains after spike
Throughput vs Latency Trade-off
Synchronous under load
- Latency constant until capacity hit
- At capacity: reject excess
- Throughput capped
- No backlog after spike
Asynchronous under load
- All requests accepted
- Latency grows with queue depth
- Backlog must drain after spike
- Recovery time depends on spike duration
Neither universally better
- User-facing, latency-sensitive → sync with backpressure
- Background processing, eventual completion OK → async

Hybrid: Accept and queue, but set max depth. Exceed threshold → reject. Buffering for normal spikes, bounded latency.
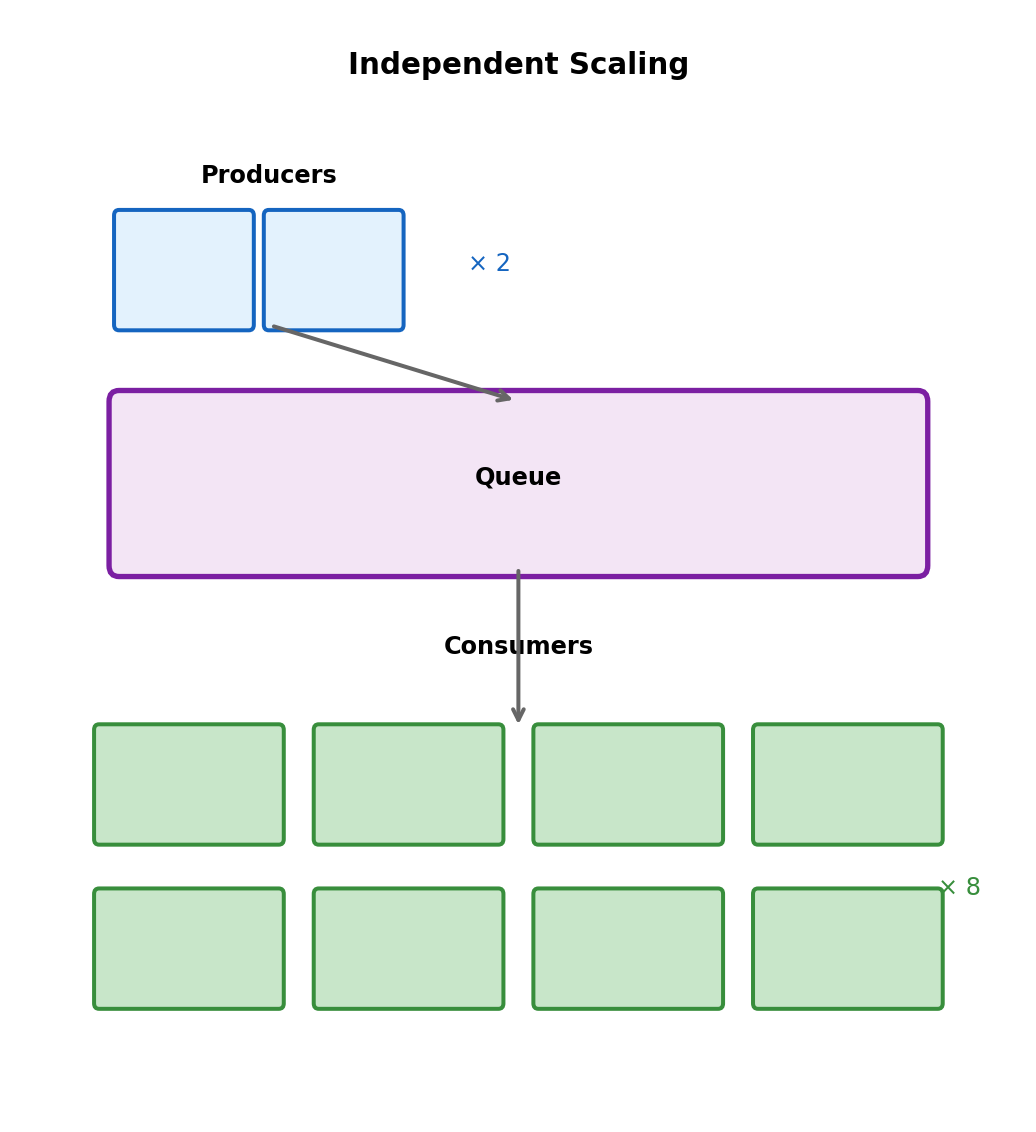
Independent Scaling
Synchronous: Scaling coupled
Same process receives and processes. Add capacity for processing → also add receiving capacity (maybe don’t need).
Queue-based: Scale each tier independently
Producers: 2 instances (receiving is fast)
↓
┌───────────┐
│ Queue │
└───────────┘
↓
Consumers: 8 instances (processing is slow)- Add producers for request volume
- Add consumers for processing throughput
- Remove consumers when queue empty (cost savings)
Lambda auto-scales on queue depth:
- Depth grows → more concurrent executions
- Queue empties → scale to zero
- Pay only for actual processing
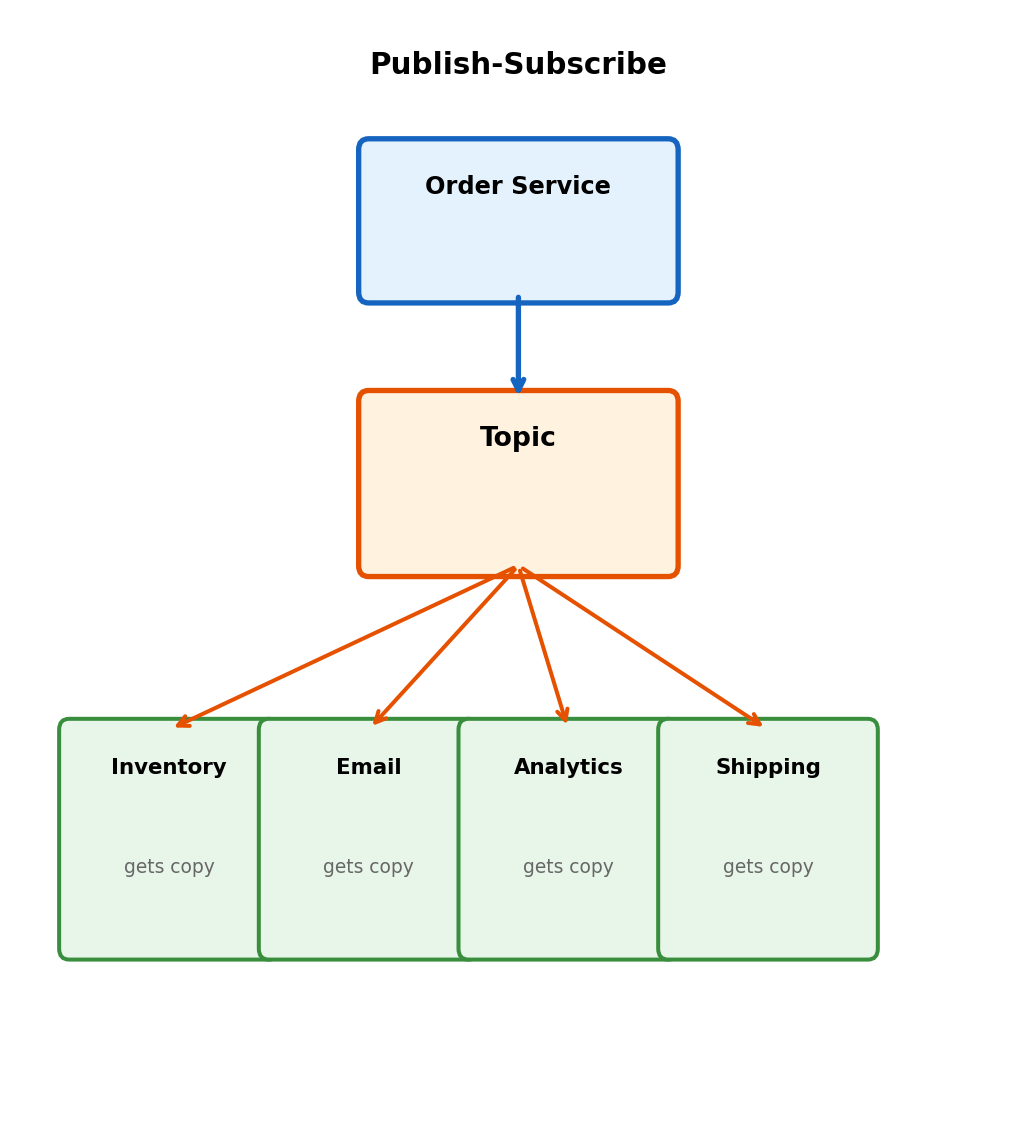
Fan-Out: One Event, Multiple Consumers
Order placed → need to:
- Update inventory
- Send confirmation email
- Record analytics
- Notify shipping
Point-to-point queue
Each message → one consumer. Multiple services need event?
- Producer sends to multiple queues, or
- One consumer forwards to others
Couples producer to knowledge of all consumers.
Publish-subscribe
Producer publishes to topic. All subscribers get copy.
Producer → Topic
↓ ↓ ↓ ↓
Inv Email Analytics Ship- Publish once
- Add consumer → no producer change
- Producer doesn’t know (or care) who subscribes
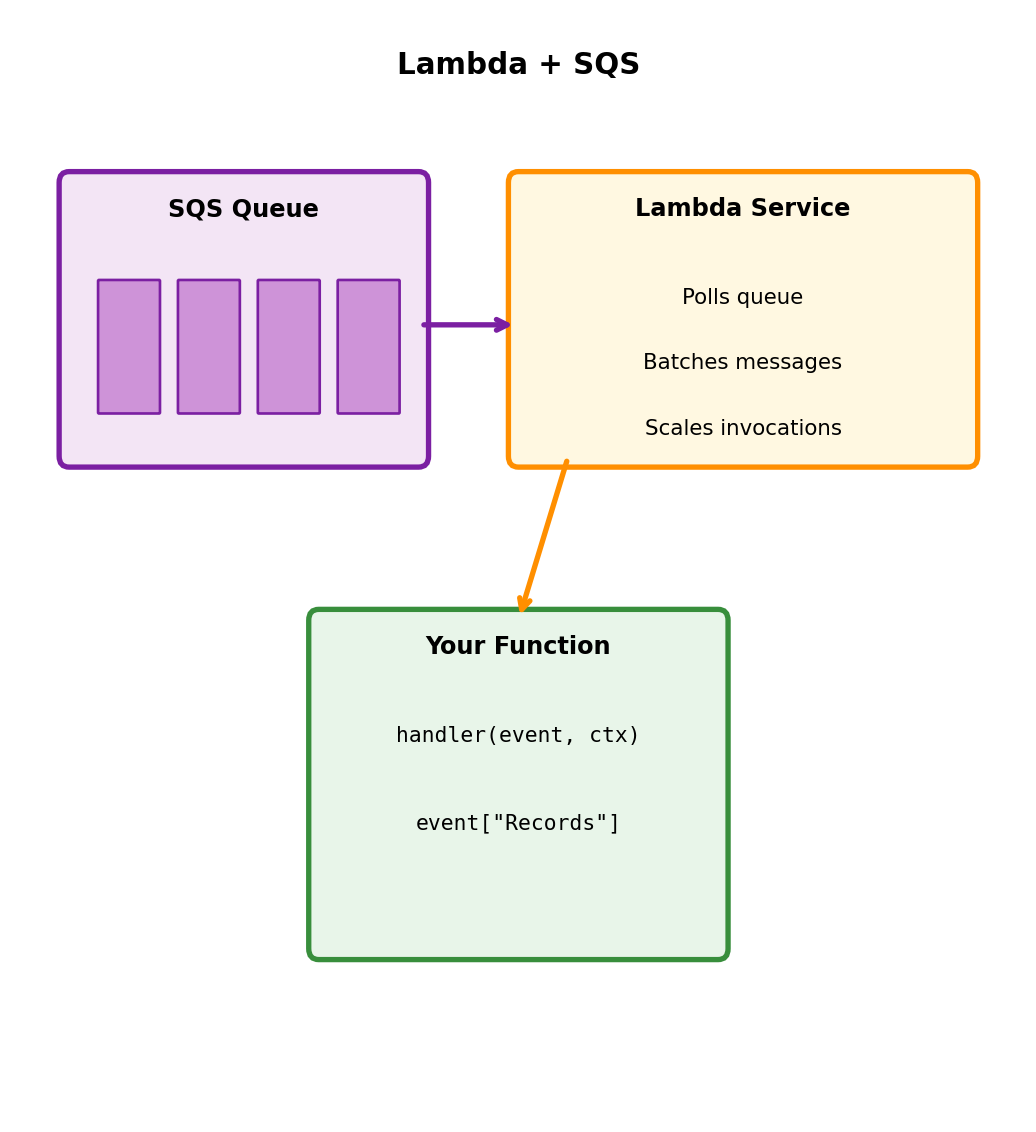
Lambda + SQS Integration
Lambda polls SQS automatically via event source mapping.
No polling code needed
def handler(event, context):
for record in event['Records']:
body = json.loads(record['body'])
process_order(body)
# Success = messages deleted
# Exception = messages return to queueLambda service handles:
- Long polling
- Batching (1-10,000 messages)
- Scaling based on queue depth
- Visibility timeout
- Retry on failure
Batch size trade-off:
- Larger: Efficient (amortize cold start), harder failure handling
- Smaller: Simpler errors, more overhead
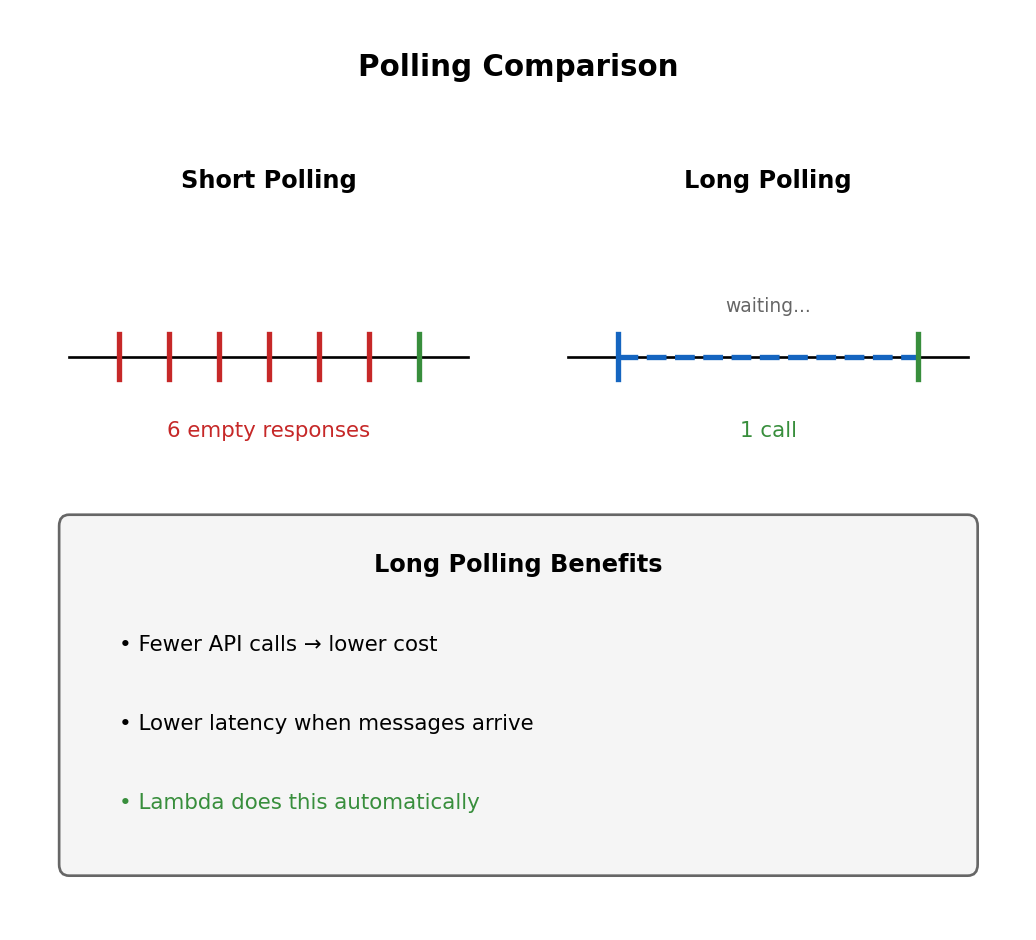
Long Polling
Short polling (default)
- Returns immediately, even if empty
- Many empty responses when queue idle
- Wasted API calls
Long polling
- Waits up to 20 seconds for messages
- Returns immediately when messages arrive
- Fewer calls, lower cost
# Short poll
response = sqs.receive_message(
QueueUrl=QUEUE_URL,
MaxNumberOfMessages=10
)
# Long poll
response = sqs.receive_message(
QueueUrl=QUEUE_URL,
MaxNumberOfMessages=10,
WaitTimeSeconds=20
)Lambda uses long polling automatically.
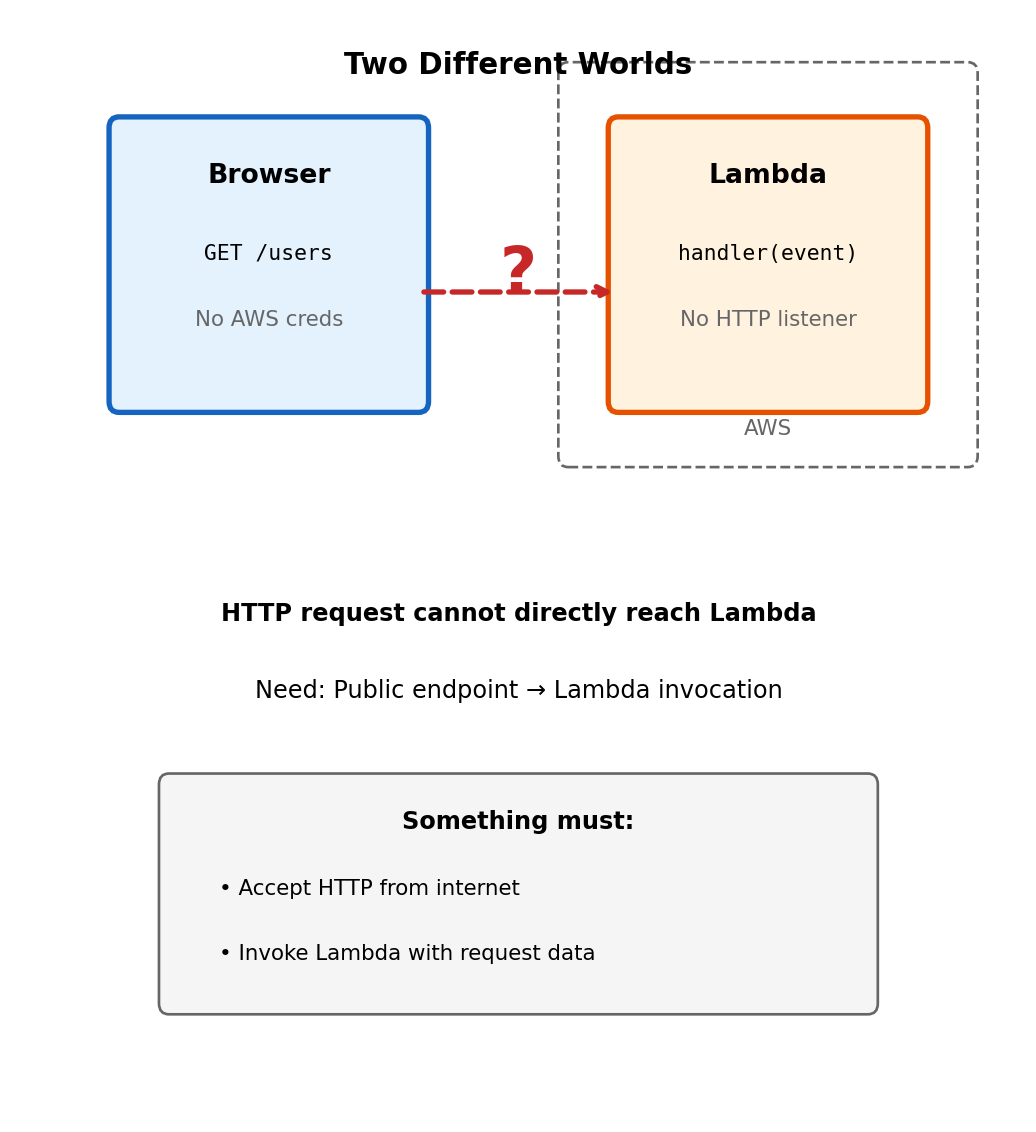
Lambda Runs Inside AWS, Not on the Internet
Lambda functions and HTTP requests live in different worlds
Lambda functions execute within AWS infrastructure. They can be invoked by AWS services (S3 events, SQS messages), but don’t listen on HTTP ports and don’t have public URLs.
# Your Lambda function
def handler(event, context):
return {'statusCode': 200, 'body': 'Hello'}How does a user’s HTTP request reach this function?
Direct Lambda invocation requires AWS credentials:
import boto3
lambda_client = boto3.client('lambda')
response = lambda_client.invoke(
FunctionName='my-function',
Payload=json.dumps({'name': 'test'})
)This works for service-to-service communication within AWS. But a browser making GET https://myapi.com/users cannot invoke Lambda directly - it doesn’t have AWS credentials, and Lambda isn’t listening on an HTTP port.
Connecting HTTP clients to Lambda requires something that accepts HTTP requests from the public internet and translates them into Lambda invocations.
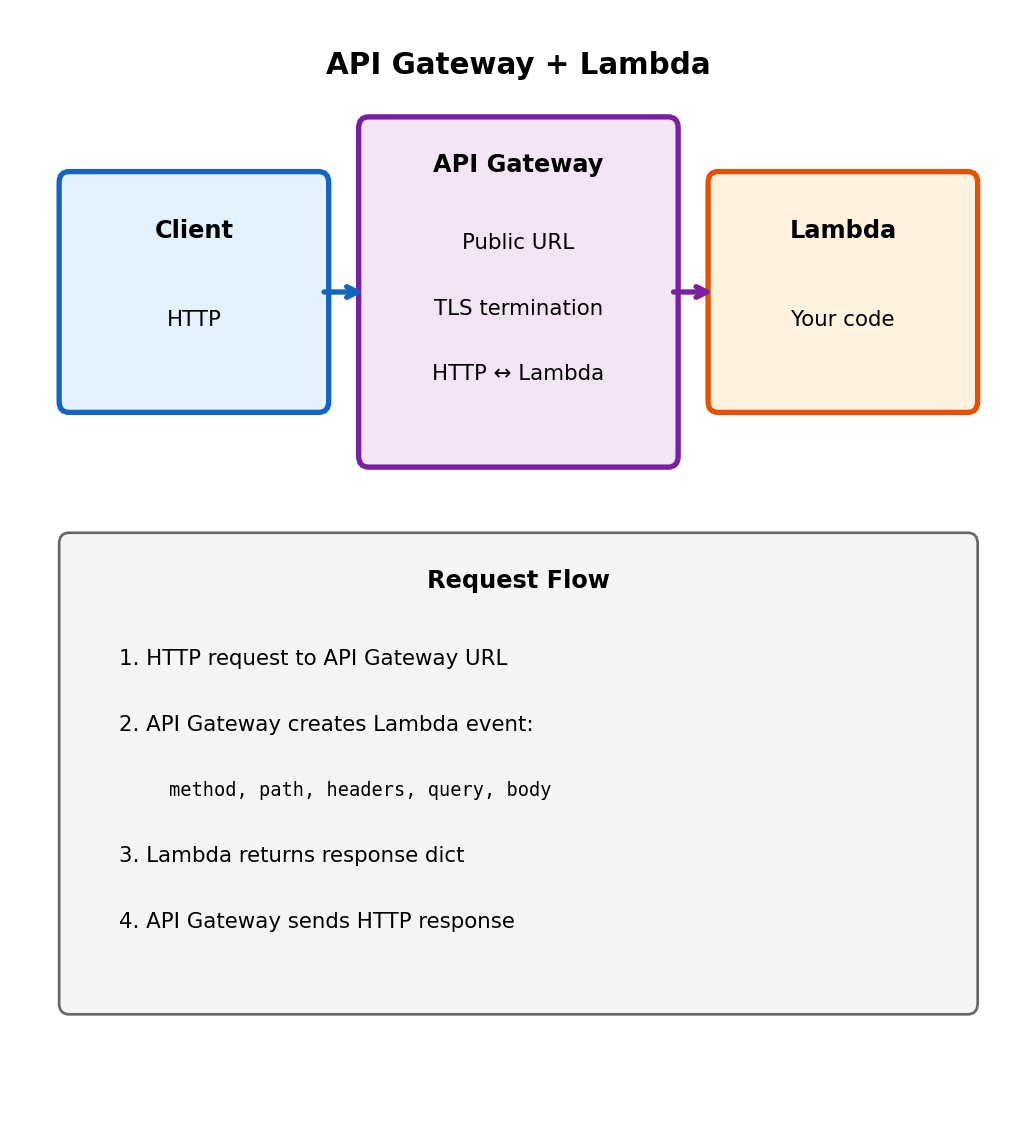
API Gateway Bridges HTTP and Lambda
API Gateway is a managed reverse proxy
It accepts HTTP requests at a public URL and routes them to backend services. For Lambda, it translates HTTP requests into Lambda invocations and Lambda responses back into HTTP responses.
https://abc123.execute-api.us-east-1.amazonaws.com/prod/users
└── API Gateway endpoint ──┘ └── path ──┘What happens on each request:
- Client sends HTTP request to API Gateway URL
- API Gateway validates request (optional)
- API Gateway invokes Lambda with event containing HTTP details
- Lambda executes, returns response object
- API Gateway translates response to HTTP
- Client receives HTTP response
The Lambda function never opens a port, never manages connections, never deals with TLS. API Gateway handles the HTTP protocol; Lambda handles the business logic.
You deploy the function, API Gateway provides the URL.
API Gateway Does More Than Route Requests
A reverse proxy handles cross-cutting concerns
Things every API needs, but you don’t want to implement in every function:
Authentication - Verify identity before code runs
- API keys (simple, but not secure alone)
- IAM authentication (for AWS-to-AWS)
- JWT tokens from Cognito or custom authorizer
- Request rejected at gateway if auth fails → Lambda never invoked
Rate limiting - Protect backend from overload
- Requests per second limits
- Burst allowances
- Per-client quotas via API keys
Request validation - Reject malformed requests early
- Required parameters
- Schema validation
- Fail at gateway, not in your function
Each of these protects your Lambda function. Invalid or excessive requests are rejected before they consume Lambda execution time (and cost).
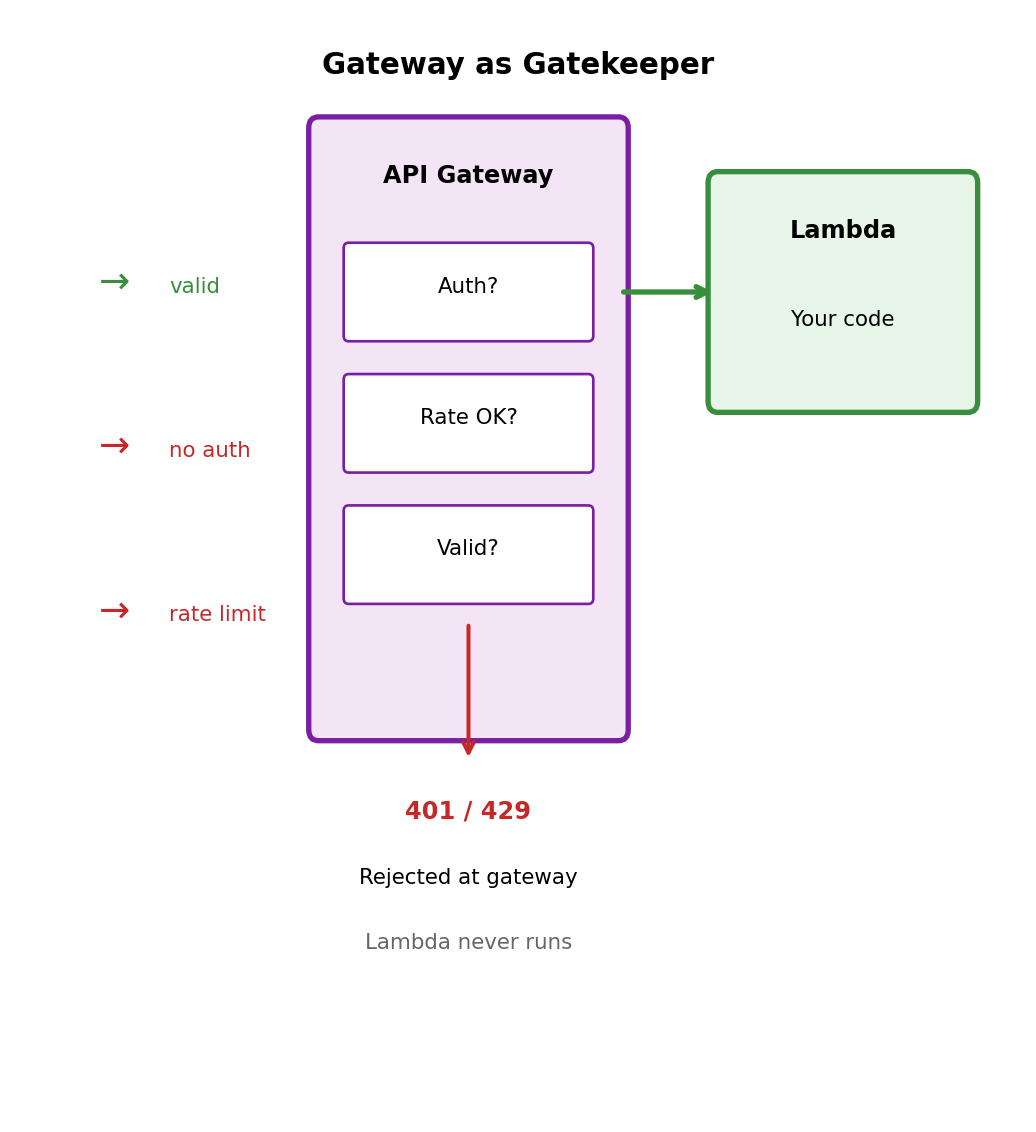
Rate Limiting Protects Your Backend
Without rate limiting
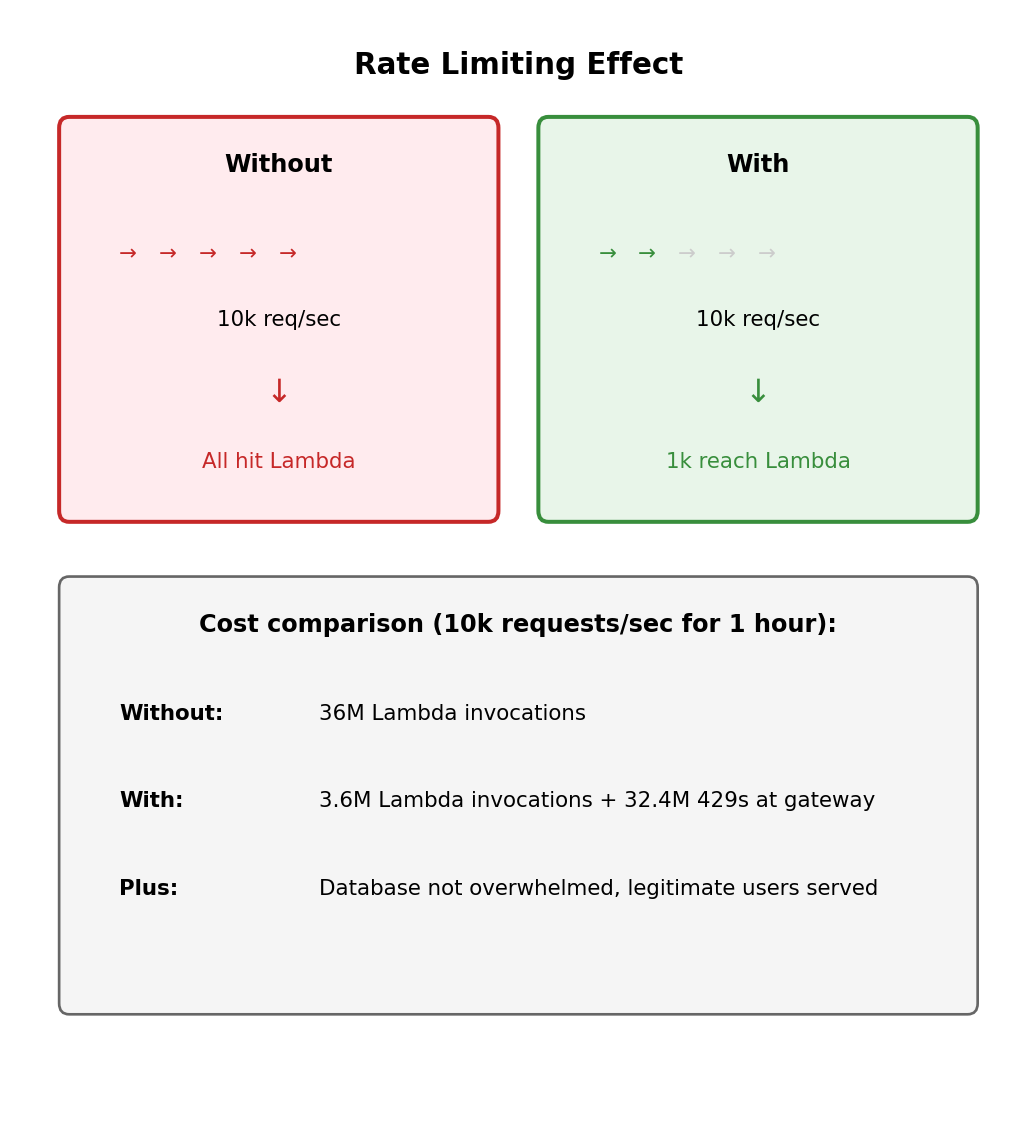
Your Lambda function is invoked for every request. Malicious or misconfigured client sends 10,000 requests/second:
- 10,000 Lambda invocations/second
- Each invocation costs money
- Downstream resources (database) overwhelmed
- Legitimate users affected
With rate limiting at the gateway
Account default: 10,000 req/sec
This API: 1,000 req/sec
/expensive-endpoint: 100 req/secExcess requests receive HTTP 429 (Too Many Requests) immediately. They never reach Lambda, never hit your database, never cost you Lambda execution fees.
HTTP/1.1 429 Too Many Requests
Retry-After: 1
{"message": "Rate limit exceeded"}Client receives clear signal to back off. Gateway absorbed the attack; backend unaffected.
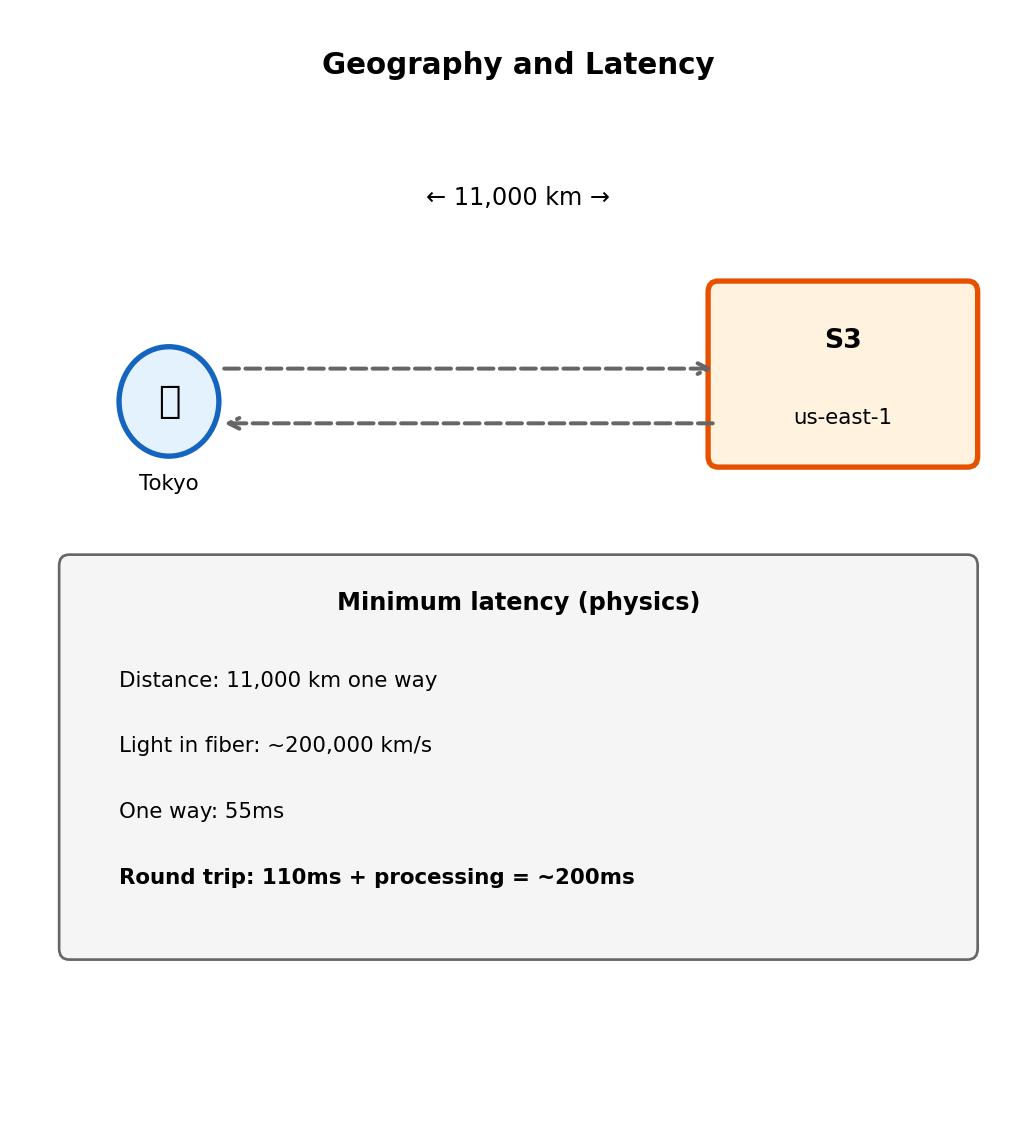
Static Content Latency: Geography Matters
S3 bucket location affects user experience
Images, CSS, JavaScript bundles, user-uploaded documents. S3 bucket is in us-east-1 (Virginia).
User in Tokyo requests an image:
- Request travels ~11,000 km to Virginia
- S3 retrieves object
- Response travels ~11,000 km back
- Round trip: 150-200ms minimum (speed of light)
For a web page loading 50 assets, that’s 50 × 200ms of latency-bound requests. Even with parallel loading, the page feels slow.
Latency here is physics, not performance.
Light travels at ~200,000 km/s through fiber. Tokyo to Virginia is 11,000 km. That’s 55ms one way, minimum. No optimization can beat the speed of light.
Reducing this latency requires putting content closer to users.
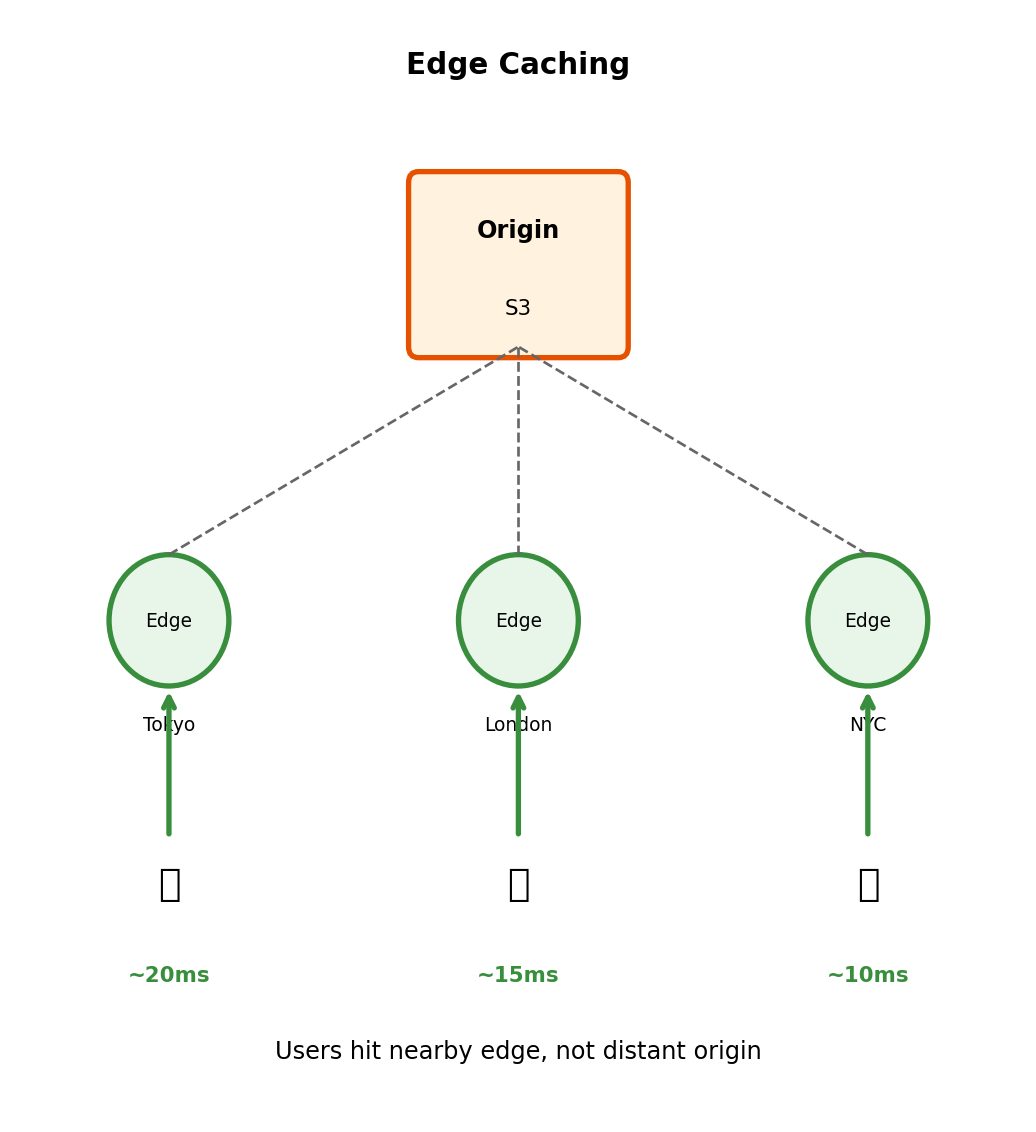
Edge Caching: Content Closer to Users
Content Delivery Network (CDN) concept
Instead of one origin in one region, cache copies at edge locations around the world. When a user requests content:
- Request goes to nearest edge location (low latency)
- If edge has cached copy → return immediately
- If not → fetch from origin, cache for next request
CloudFront: AWS’s CDN
- 400+ edge locations globally
- Integrates with S3, API Gateway, custom origins
- Provides custom domain + managed TLS certificate
First request (cache miss): User in Tokyo → Tokyo edge → S3 origin → Tokyo edge → User
Total: ~200ms (fetch from origin)
Subsequent requests (cache hit): User in Tokyo → Tokyo edge → User
Total: ~20ms (served from edge)
The edge location is physically close. Most requests hit cache. Latency drops dramatically.
Cache Hit vs Cache Miss
Cache hit: Edge has the content
User → Edge: GET /images/logo.png
Edge: "I have this cached"
Edge → User: 200 OK (from cache)
Latency: ~20msEdge returns cached copy immediately. Origin not contacted. This is the fast path - and for popular content, most requests are cache hits.
Cache miss: Edge must fetch from origin
User → Edge: GET /images/new-upload.png
Edge: "Not in my cache"
Edge → Origin: GET /images/new-upload.png
Origin → Edge: 200 OK + content
Edge: Cache it for next time
Edge → User: 200 OK
Latency: ~200ms (first request)
Latency: ~20ms (subsequent requests)First user pays the origin fetch latency. All users after benefit from the cached copy.
Cache effectiveness depends on:
- How often the same content is requested
- How long content stays in cache (TTL)
- How many requests hit each edge location

Cache Configuration Decisions
TTL (Time To Live): How long to cache?
Short TTL (seconds to minutes):
- Content updates quickly reflected
- More origin fetches
- Good for: Frequently changing content
Long TTL (hours to days):
- Better cache hit ratio
- Updates take time to propagate
- Good for: Static assets that rarely change
Versioned filenames solve the TTL dilemma:
/static/app.js → TTL: 5 minutes (changes often?)
/static/app.v2.3.js → TTL: 1 year (version in name)With versioned filenames, you deploy new code with a new filename. Old cached versions don’t matter - new requests use the new filename. Set very long TTL, get both cacheability and instant updates.
Cache key: What makes a request “same”?
By default: URL path. Same path = same cached response.
Can include: Query strings, headers. But more in cache key = fewer cache hits.

CloudFront + S3 for Static Assets
Typical setup for web applications:
S3 bucket holds static files (build output, images, uploads). CloudFront distribution sits in front of the bucket. Users access files through CloudFront URL or custom domain.
Your domain: cdn.myapp.com
↓
CloudFront
↓
S3 bucket (private)Origin Access Control (OAC):
S3 bucket remains private - no public access. Only CloudFront can read from it. This prevents users from bypassing CDN and hitting S3 directly.
Benefits for your project:
- Fast asset loading globally
- Custom domain with HTTPS (managed certificate)
- S3 costs reduced (fewer direct requests)
- DDoS protection at edge
When not worth the complexity:
- Development/internal tools (single location users)
- Low traffic, infrequent access
- Content so personalized caching doesn’t help
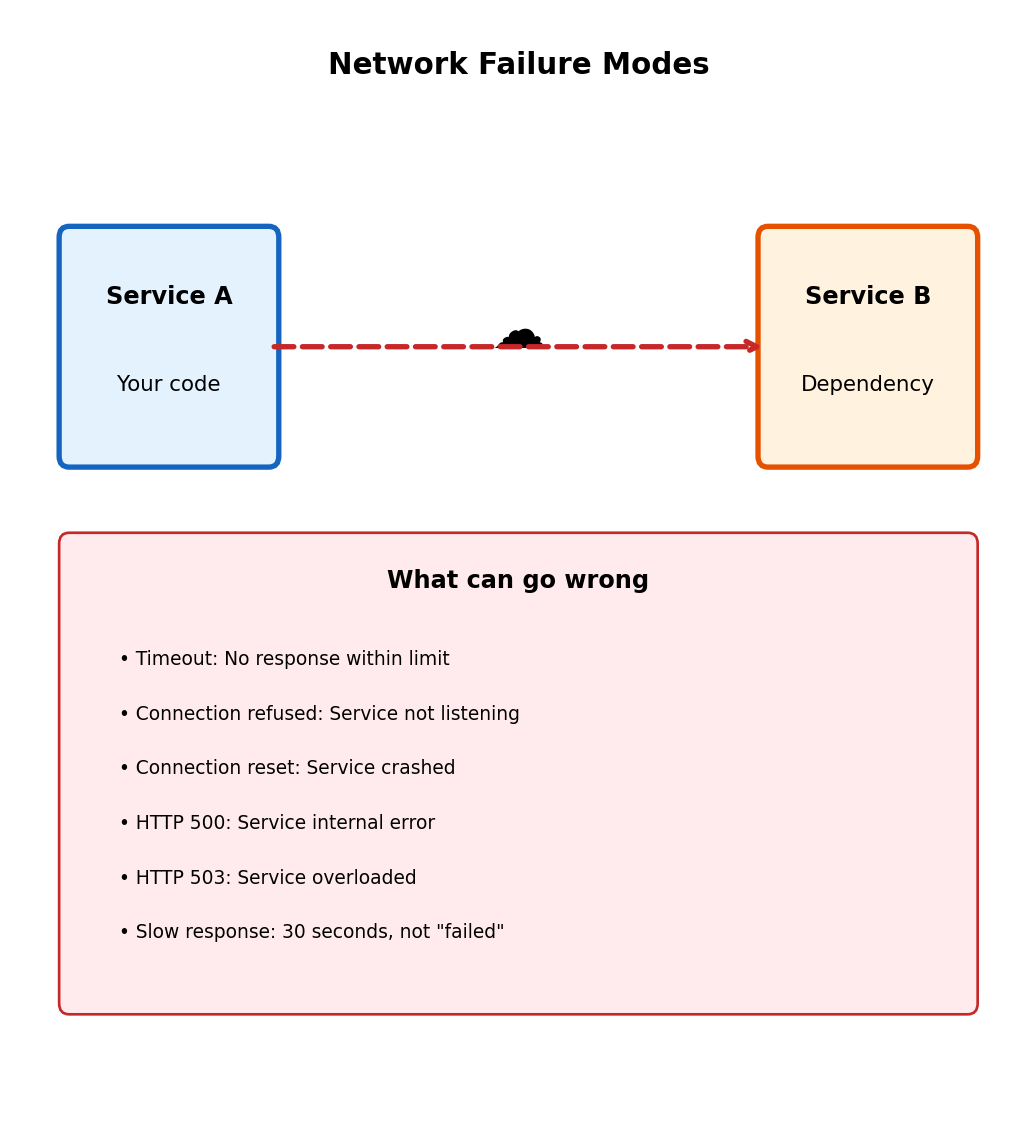
Network Calls Have Different Failure Modes Than Local Calls
Service A calls Service B over the network
Network calls introduce failure modes that don’t exist in local function calls:
- Network timeout (no response)
- Connection refused (service down)
- Connection reset (service crashed mid-response)
- HTTP 500 (service had internal error)
- HTTP 503 (service overloaded)
- Slow response (not failed, but 30 seconds)
In a local function call, you either get a result or an exception, quickly. Network calls add failure modes and latency variability.
In a service chain, failures compound:
A → B → C → D
Each hop: 99.9% success rate
Chain: 99.9% × 99.9% × 99.9% × 99.9% = 99.6%Three nines at each step gives you less than three nines end-to-end. More services = more failure points.
Failures are not exceptional - they’re expected. Design for them.
Retry: The Obvious First Response
Request failed? Try again.
def call_service():
for attempt in range(3):
try:
response = requests.get(url, timeout=5)
return response
except RequestException:
if attempt == 2:
raise
continueSome failures are transient - they go away if you retry:
- Network blip
- Service restarting
- Momentary overload
Other failures are permanent - retry won’t help:
- HTTP 400 (bad request - your fault)
- HTTP 404 (resource doesn’t exist)
- HTTP 401 (not authorized)
Retry transient failures. Don’t retry permanent ones.
if response.status_code >= 500:
# Server error - might be transient
retry()
elif response.status_code >= 400:
# Client error - our request is wrong
raise ClientError(response)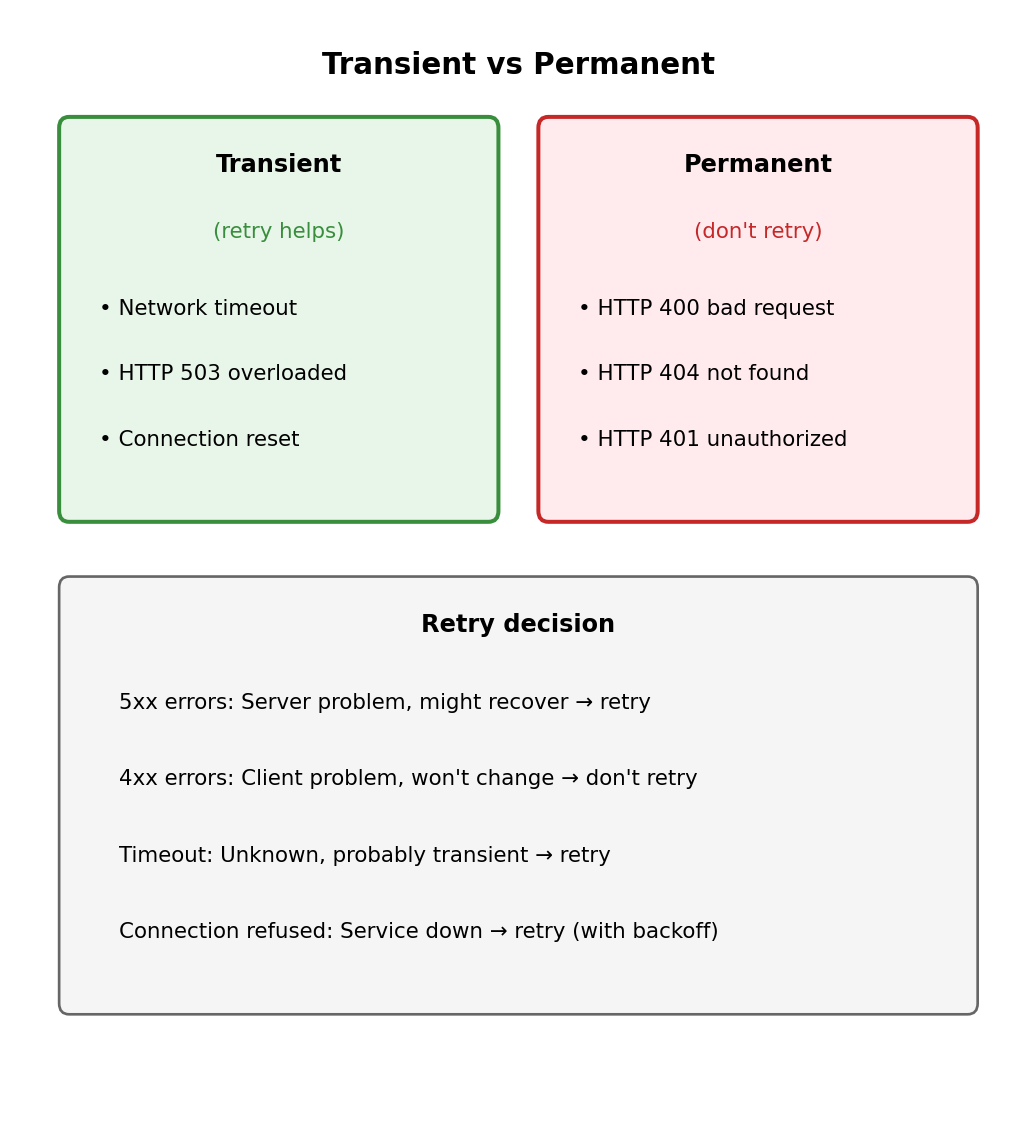
Immediate Retry Creates Thundering Herd
Service B is overloaded, returning 503s
Client 1: Request fails → immediate retry Client 2: Request fails → immediate retry Client 3: Request fails → immediate retry … Client 1000: Request fails → immediate retry
All 1000 clients retry at the same moment. Service B, already struggling, now receives another 1000 requests instantly. It fails again. All 1000 retry again.
The retry storm keeps the service down.
# This makes things worse
for attempt in range(3):
try:
return requests.get(url)
except:
continue # Retry immediatelyEven if the service could recover in 1 second, the continuous retry storm prevents recovery. Clients are “helping” by retrying, but collectively they’re causing a denial of service.

Exponential Backoff Spreads Load
Wait longer between each retry
import time
import random
def call_with_backoff(func, max_attempts=5):
for attempt in range(max_attempts):
try:
return func()
except TransientError:
if attempt == max_attempts - 1:
raise
# Wait: 1s, 2s, 4s, 8s...
delay = 2 ** attempt
time.sleep(delay)First retry after 1 second. Second retry after 2 more seconds. Third after 4 more. Exponential growth creates spacing.
But all clients still retry at the same intervals.
Client 1: Retry at t=1, t=3, t=7 Client 2: Retry at t=1, t=3, t=7 Client 3: Retry at t=1, t=3, t=7
Still clustered, just at different times. Need to break the synchronization.

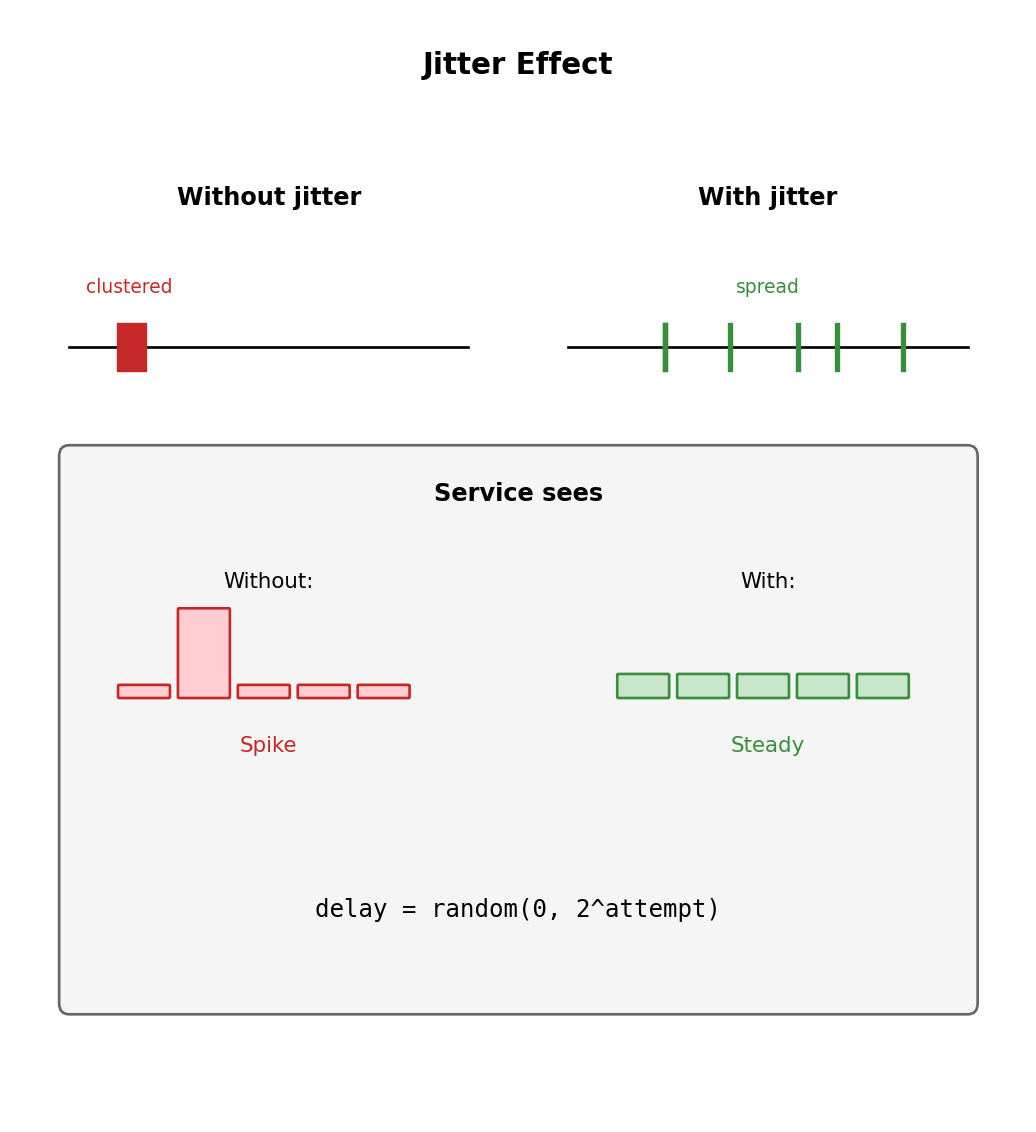
Jitter Breaks Synchronization
Add randomness to break clustering
import random
def call_with_backoff_jitter(func, max_attempts=5):
for attempt in range(max_attempts):
try:
return func()
except TransientError:
if attempt == max_attempts - 1:
raise
# Full jitter: random between 0 and max
max_delay = 2 ** attempt
delay = random.uniform(0, max_delay)
time.sleep(delay)Full jitter: Random delay between 0 and 2^attempt
Client 1: Retry at t=0.7 Client 2: Retry at t=0.2 Client 3: Retry at t=0.9
Retries spread across the window instead of clustering at one point. Service receives steady trickle instead of burst.
AWS SDK uses this by default. Most well-designed clients implement exponential backoff with jitter. If you’re building retry logic, include jitter.
Timeouts Prevent Indefinite Blocking
Every network call needs a timeout
Without timeout, a slow or unresponsive service blocks your code indefinitely. Connection stays open, thread stays blocked, resources stay consumed.
# Dangerous: No timeout
response = requests.get(url) # May never return
# Safe: Explicit timeout
response = requests.get(url, timeout=5) # Fail after 5s
# Better: Separate connect and read timeouts
response = requests.get(url, timeout=(3, 10))
# connect=3s, read=10sConnect timeout: How long to wait for connection establishment. Service down? Fail fast.
Read timeout: How long to wait for response data. Service slow? Don’t wait forever.
Timeout values depend on what you’re calling:
- Health check: 1-2 seconds
- Database query: 5-30 seconds
- Long-running API: Set based on expected duration + buffer
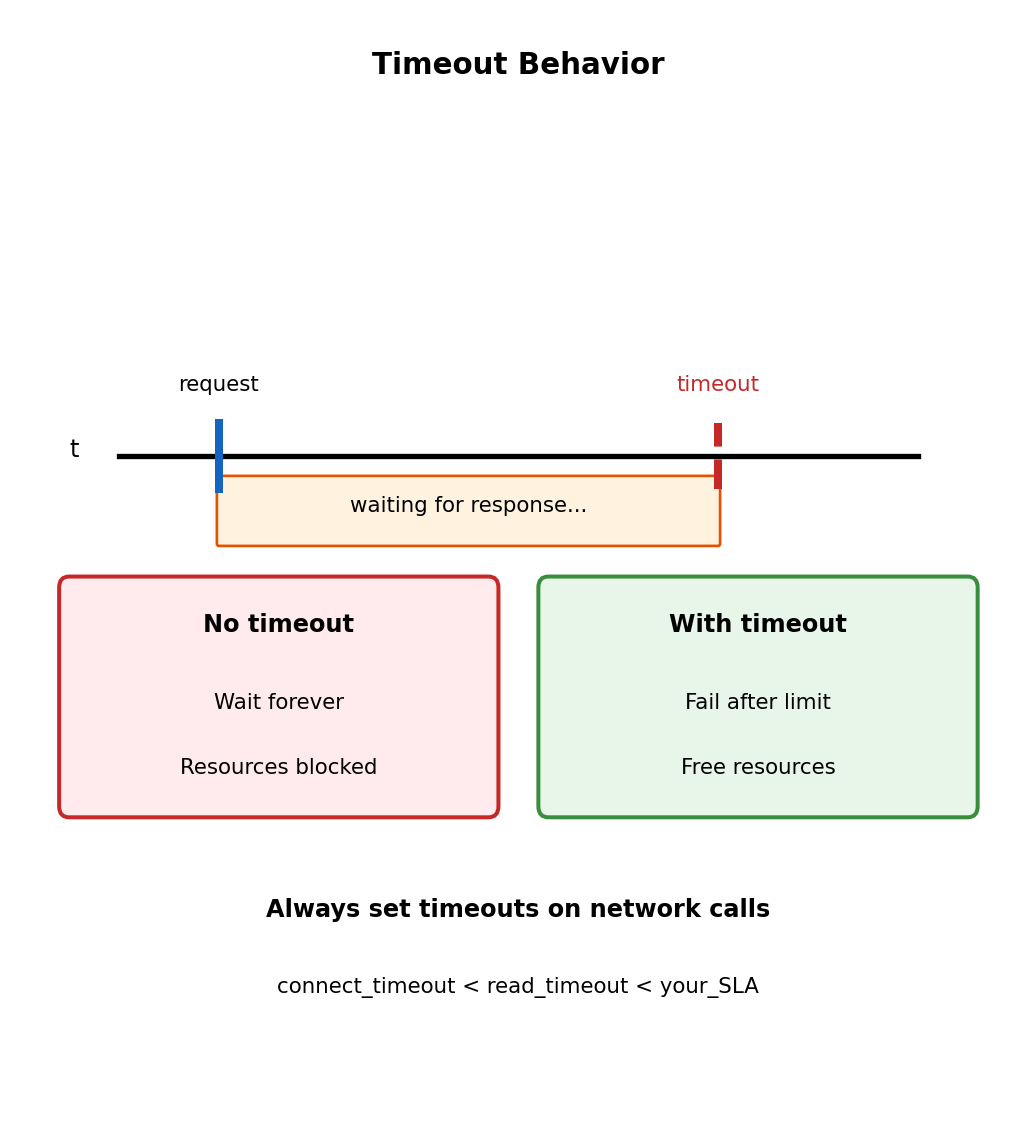
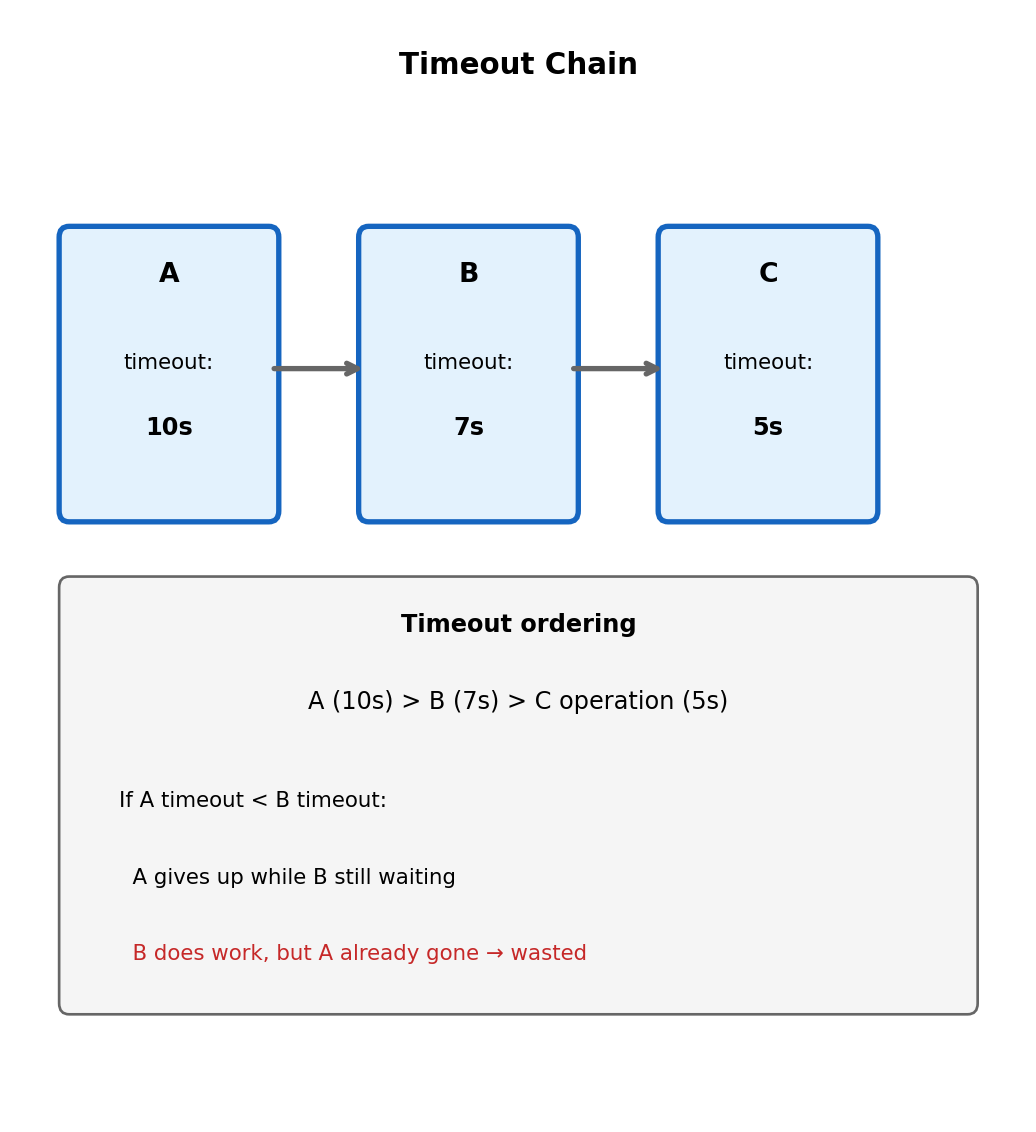
Timeout Ordering in Service Chains
A calls B calls C
Each service has a timeout for its downstream call:
- C’s operation takes up to 5s
- B’s timeout calling C: 7s (5s + buffer)
- A’s timeout calling B: 10s (7s + buffer)
If A’s timeout < B’s timeout:
A gives up at 8s. B is still waiting for C (up to its 7s timeout). When C finally responds to B, B responds to… nothing. A already gave up. Work wasted.
Rule: Caller timeout > callee timeout
A timeout (10s) > B timeout (7s) > C operation (5s)This ensures:
- If C is slow, B times out first
- If B is slow, A times out after B would have
- Work isn’t wasted on requests that caller abandoned
Circuit Breaker: Stop Calling Failing Services
Retries have a limit
Even with backoff and jitter, you’re still calling a service that’s failing. If the service is down for 5 minutes, you’ll spend 5 minutes making failing calls (with exponential waits).
Meanwhile:
- Your resources are consumed waiting
- Your latency suffers
- You’re adding load to a struggling service
Circuit breaker: Fail fast when service is unhealthy
Track success/failure rate. If failure rate exceeds threshold, stop calling - return error immediately without making the request.
# CLOSED: Normal operation
# Requests flow through, track failures
# OPEN: Service is failing
# Reject requests immediately, don't call service
# HALF-OPEN: Test recovery
# Allow one request through to test
# Success → close circuit
# Failure → stay open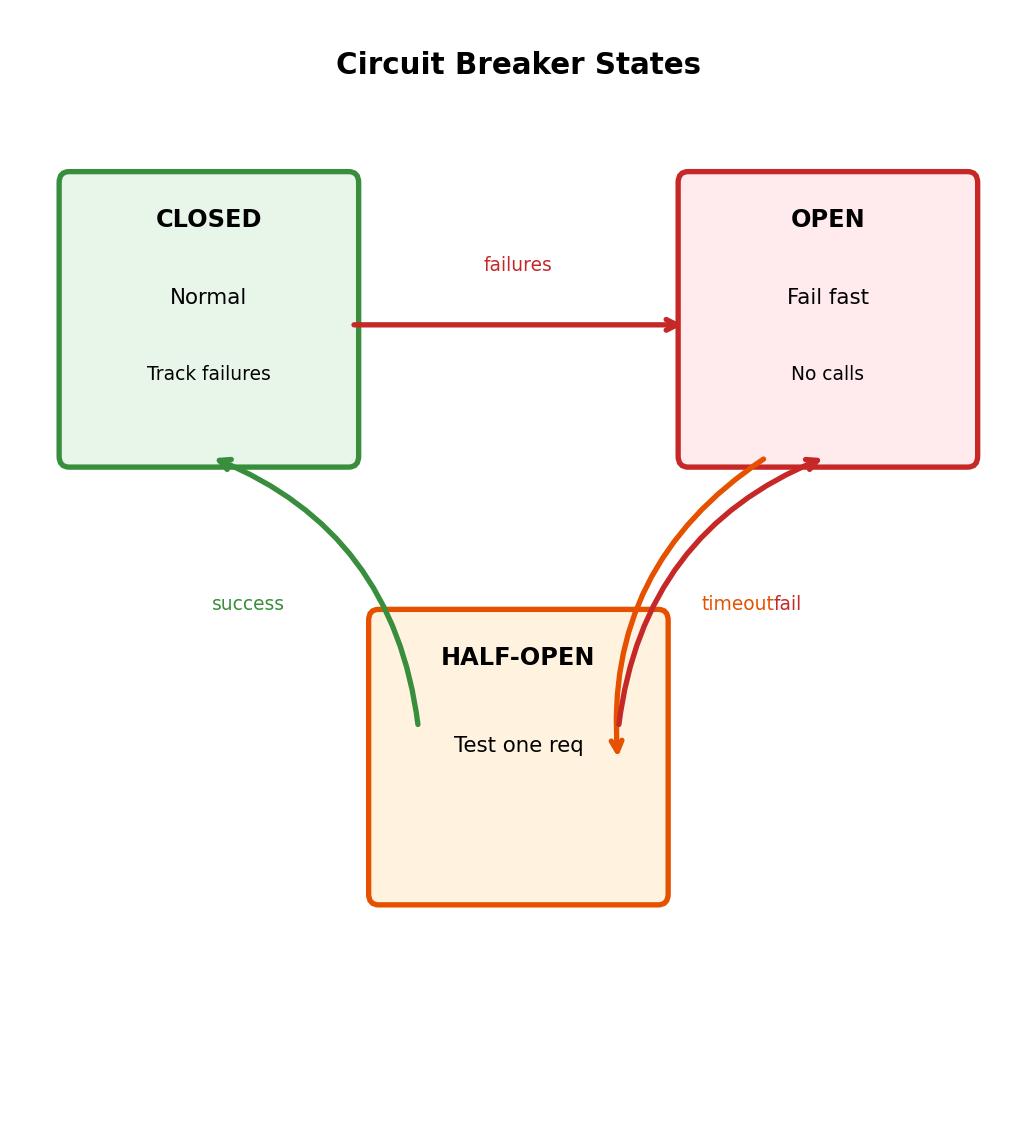
Combining Resilience Patterns
These patterns work together:
@circuit_breaker(threshold=5, timeout=30)
def call_service_b():
for attempt in range(3):
try:
response = requests.get(
url,
timeout=(3, 10) # Connect, read
)
response.raise_for_status()
return response.json()
except Timeout:
delay = random.uniform(0, 2 ** attempt)
time.sleep(delay)
continue
except HTTPError as e:
if e.response.status_code >= 500:
delay = random.uniform(0, 2 ** attempt)
time.sleep(delay)
continue
raise # 4xx = don't retry
raise ServiceUnavailable()Order of defense:
- Timeout prevents waiting forever
- Retry (with backoff + jitter) handles transient failures
- Circuit breaker stops calling if failures persist
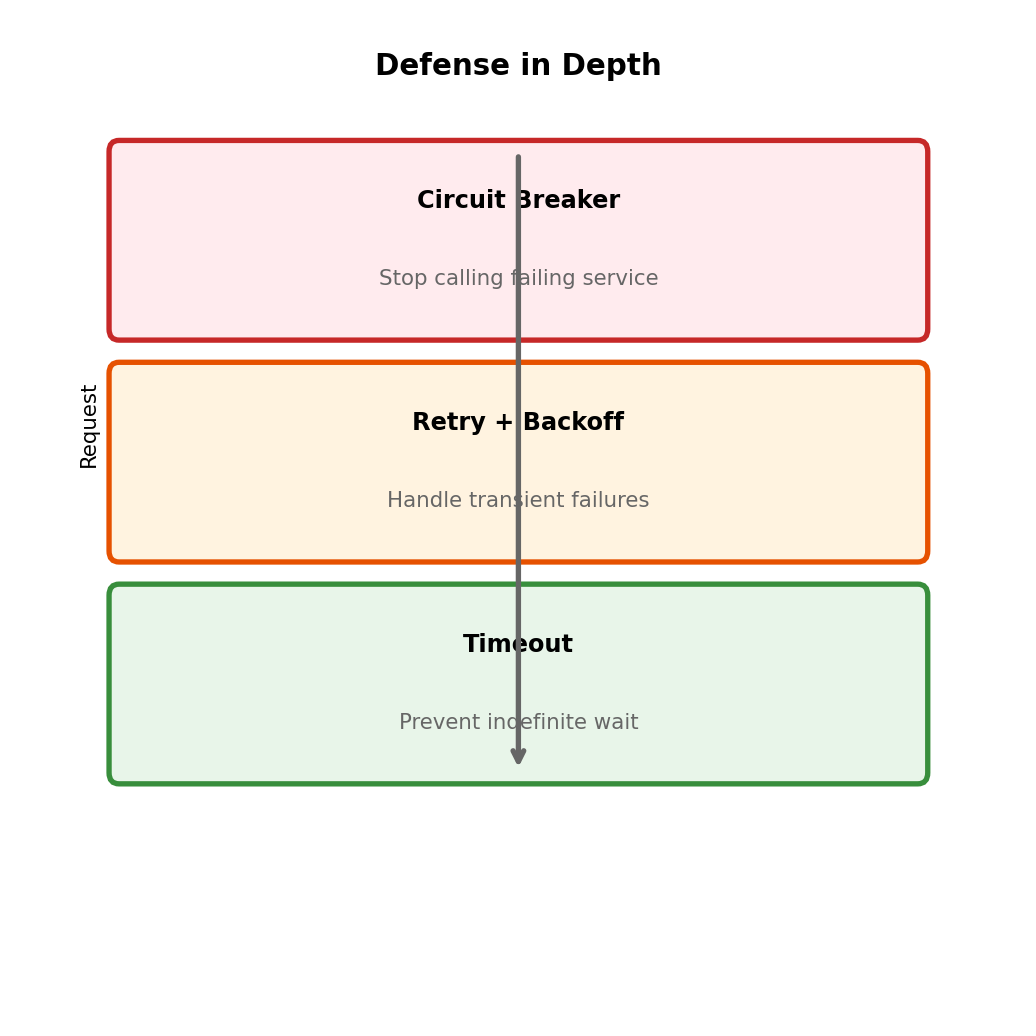
Each layer catches different failures:
- Timeout: Individual slow calls
- Retry: Occasional failures
- Circuit breaker: Sustained outages
Step Functions: Workflow Orchestration
What it is
AWS service for coordinating multi-step workflows. Define states and transitions visually or in JSON. AWS executes the workflow, handling retries and state persistence.
When it helps:
- Complex workflows with branching logic
- Long-running processes (hours, days)
- Need to pause for human approval
- Parallel execution with aggregation
- Visual debugging of workflow state
When it’s overkill:
Simple async doesn’t need it:
API → SQS → Lambda
vs
API → Step Functions → LambdaThe SQS pattern is simpler, cheaper, and sufficient for most cases. Step Functions adds value when the coordination logic itself is complex - not just “process this later.”
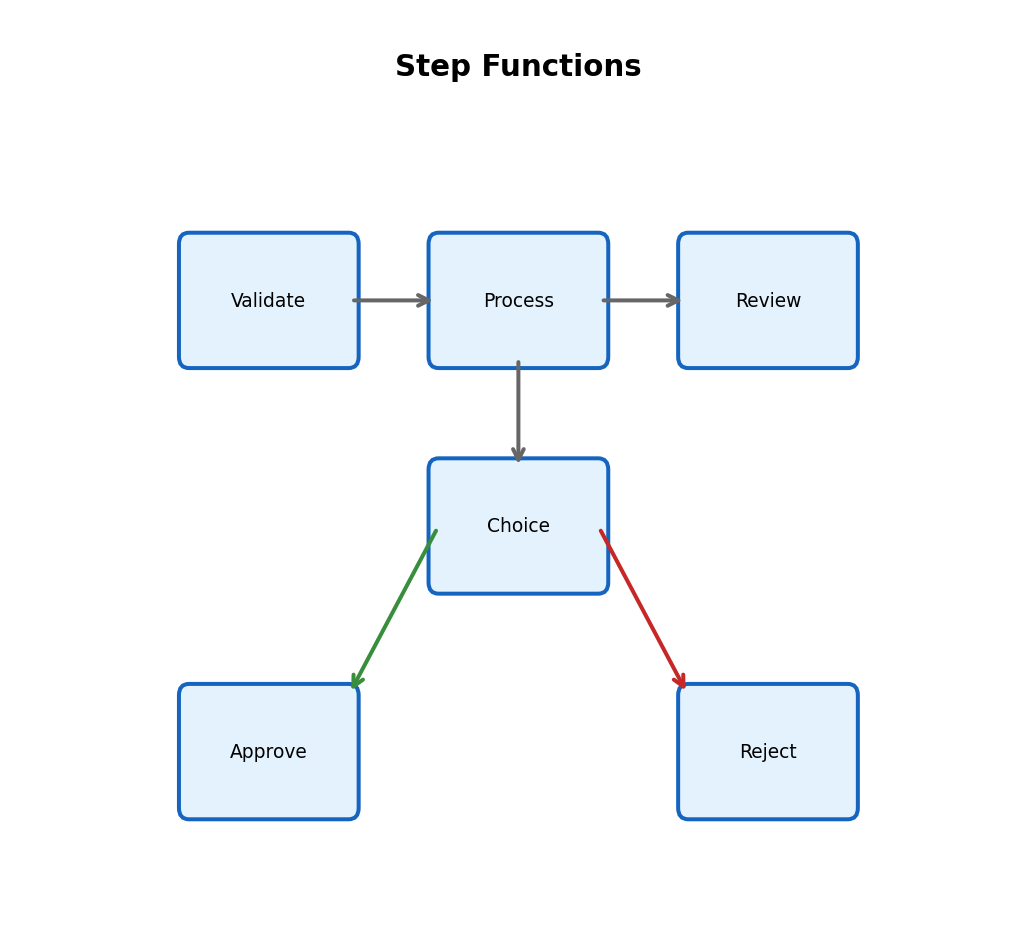
Use for: Order processing with approvals, multi-stage data pipelines, anything with complex branching.
Skip for: Simple “do this later” tasks.
EventBridge: Event Routing
What it is
Serverless event bus with content-based routing. Events from many sources, rules determine where they go.
How it differs from SNS:
- SNS: Publish to topic, all subscribers get message
- EventBridge: Publish event, rules filter and route
// EventBridge rule: Route high-value orders
{
"source": ["orders"],
"detail-type": ["order.placed"],
"detail": {
"amount": [{"numeric": [">=", 1000]}]
}
}Only orders with amount >= 1000 trigger this rule. Other orders go elsewhere (or nowhere).
Built-in event sources:
AWS services emit events to EventBridge automatically. EC2 instance state changes, S3 events, CodePipeline status - all available without configuration.
When SNS is enough: All subscribers need all messages. No filtering. Simple fan-out. Use SNS + SQS.
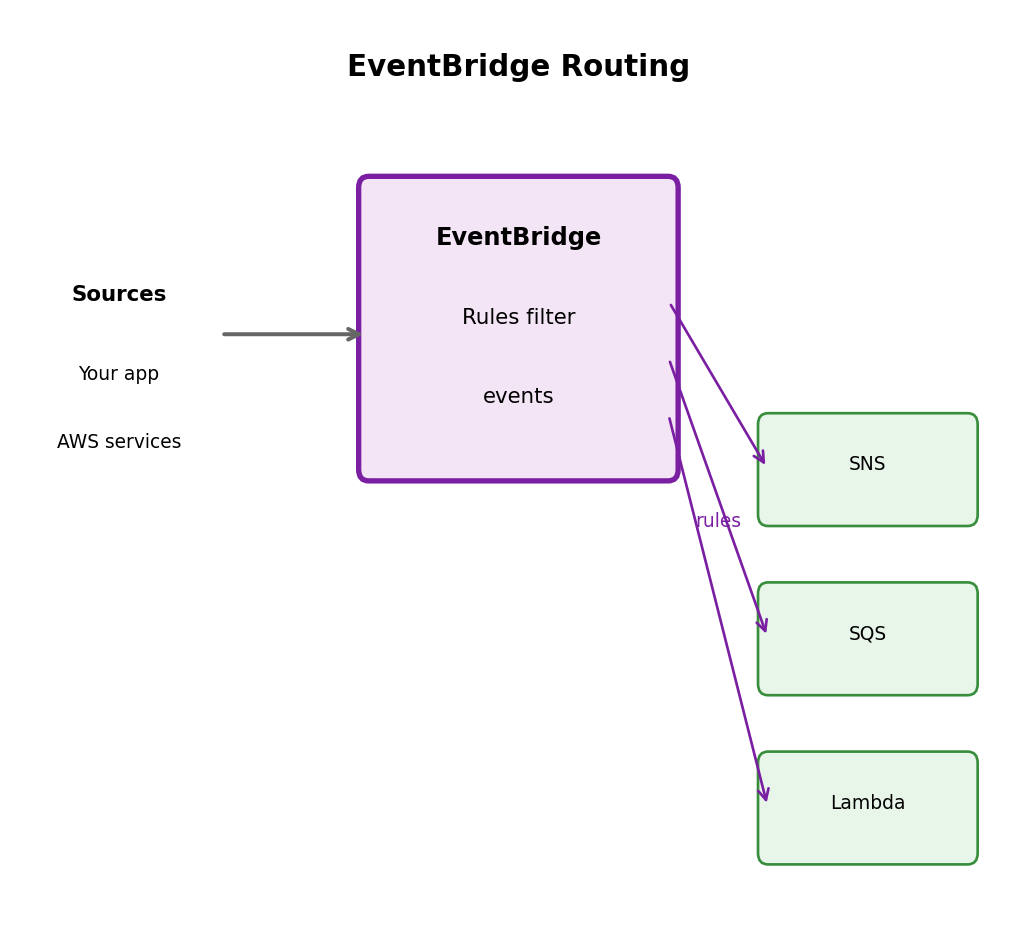
Also useful for: Scheduled triggers (cron replacement). rate(5 minutes) or cron(0 12 * * ? *).
Kinesis: Real-Time Streaming
What it is
Ingest and process continuous data streams in real-time. Unlike SQS (message queue), Kinesis is a log - data is retained and can be replayed.
Kinesis behaves differently than SQS
SQS is a work queue: process a message, delete it, it’s gone. Consumers compete - each message goes to one consumer. Order isn’t guaranteed (Standard) or is strict but low throughput (FIFO).
Kinesis is a stream: data stays for 24 hours (configurable to 365 days). Consumers read independently at their own position - same data can be processed by analytics, archival, and alerting systems simultaneously. Order is guaranteed within a shard.
When Kinesis characteristics matter:
- Real-time analytics (multiple consumers, same data)
- Log aggregation (retain for replay/audit)
- Event sourcing (rebuild state by replaying events)
- Ordered processing at high throughput
When SQS characteristics are sufficient:
Process once, delete, move on. Single consumer per message. No replay needed. Most async processing fits this model - use SQS by default.
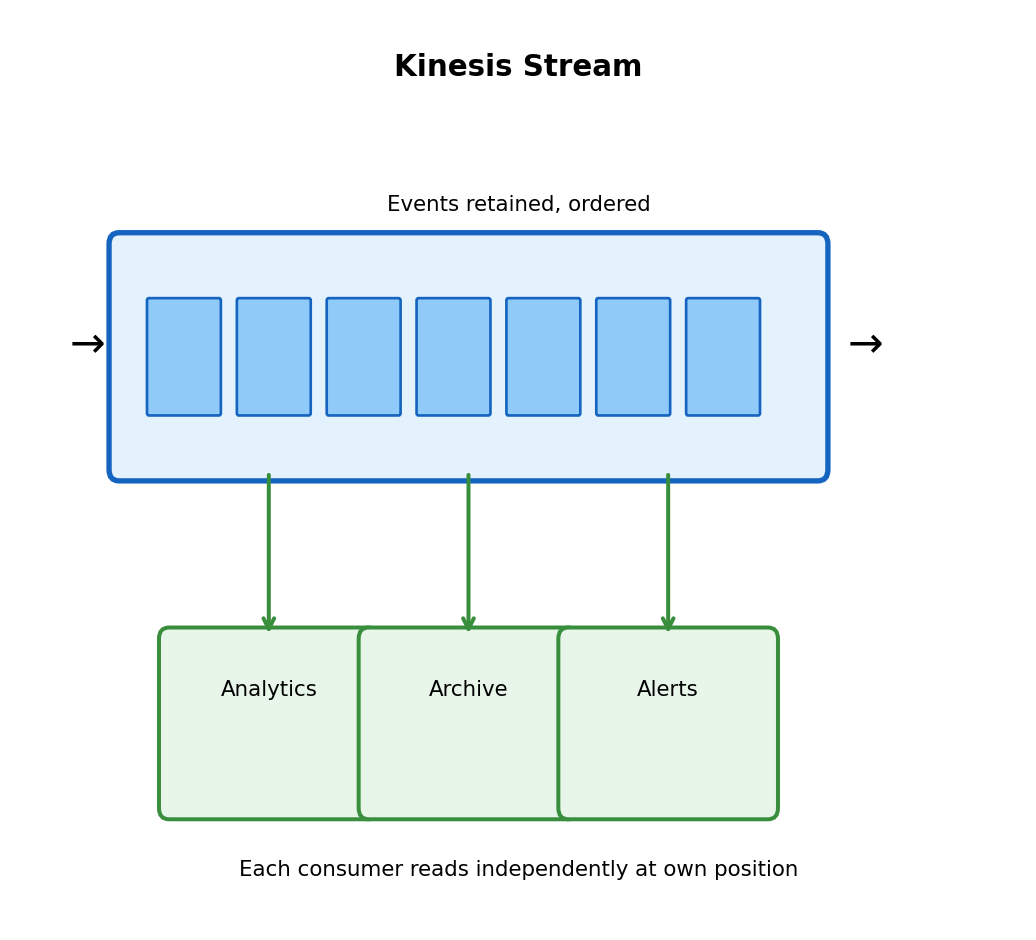
Mental model: Kinesis = distributed log (retain, replay, multiple readers). SQS = work queue (process, delete, compete).
Choosing Integration Patterns
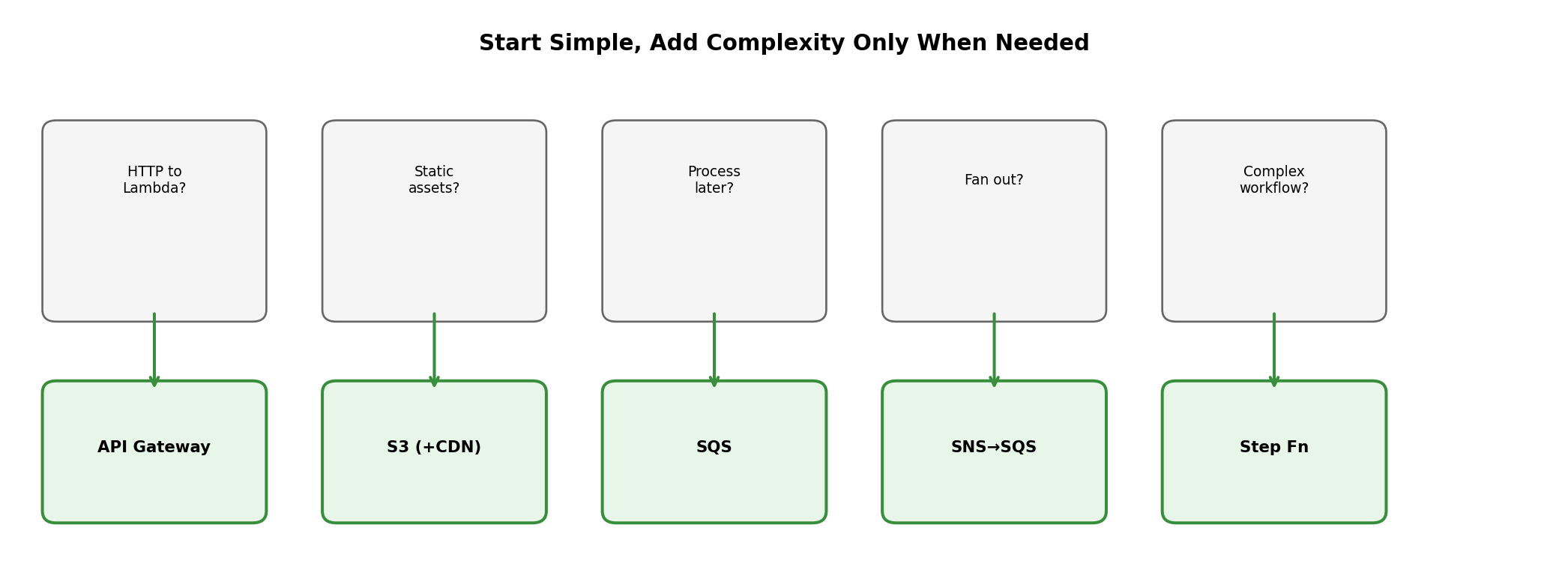
Default patterns for most projects:
- Lambda behind API Gateway for APIs
- S3 for file storage (+ CloudFront if users are distributed)
- SQS for async processing
- SNS → SQS for fan-out
EventBridge, Step Functions, Kinesis solve specific problems. Reach for them when you have those problems - not by default.
A Content Moderation Pipeline
User uploads an image. Application must:
- Store the original image
- Analyze content for policy violations (AWS Rekognition)
- Run custom classification model (application-specific categories)
- Combine results and update database
- Notify user of outcome
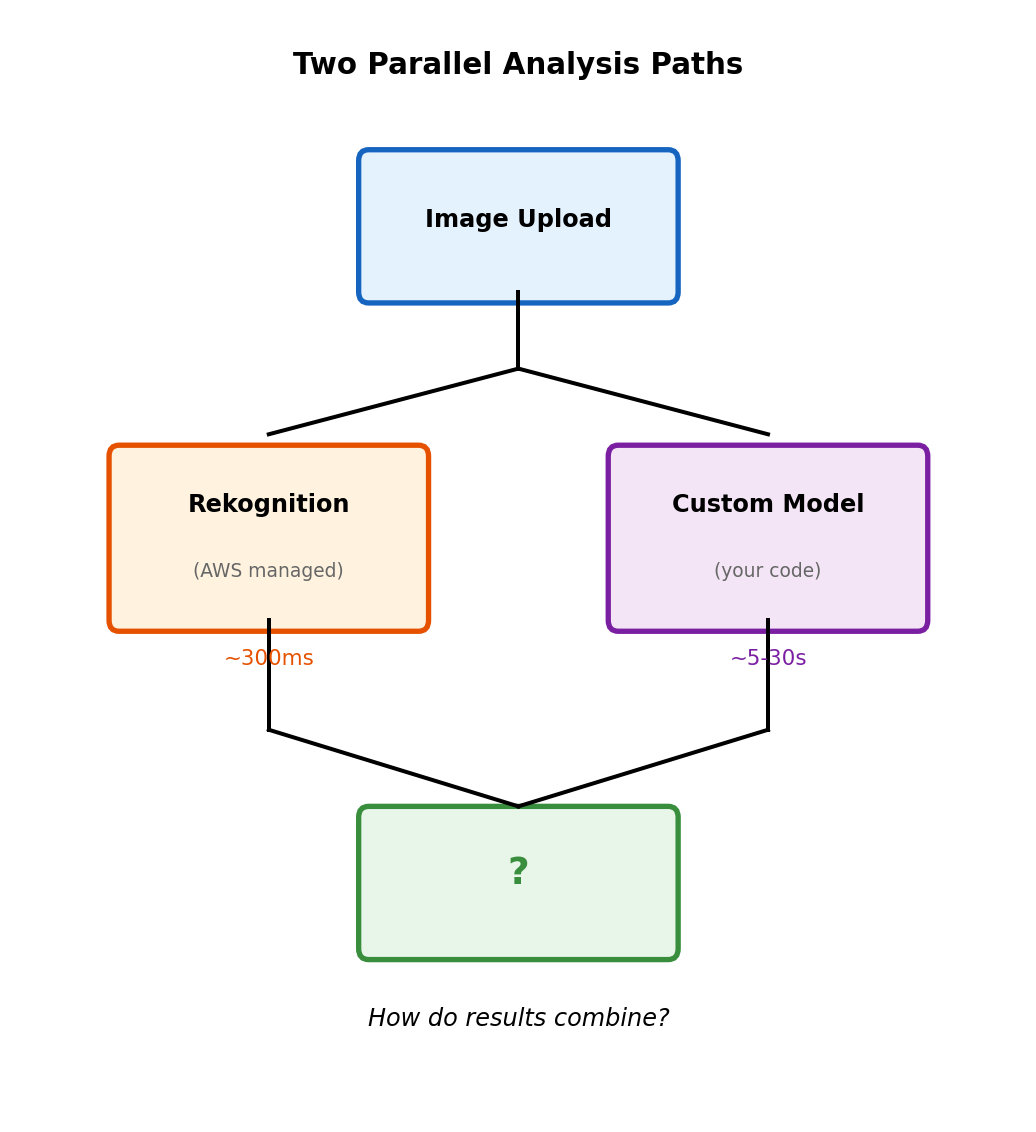
Two analysis paths run in parallel:
- Rekognition: Managed service, ~200-500ms typical
- Custom model: Your Lambda + model, ~2-30 seconds depending on complexity
Neither path knows about the other. Both produce results that must be combined before the user sees an outcome.
This is a coordination problem.
The upload is synchronous (user waits for acknowledgment). The analysis is asynchronous (user doesn’t wait). The notification is eventually synchronous (user sees result).
How do you decompose this into services? Where do boundaries fall? What coordinates the parallel work?
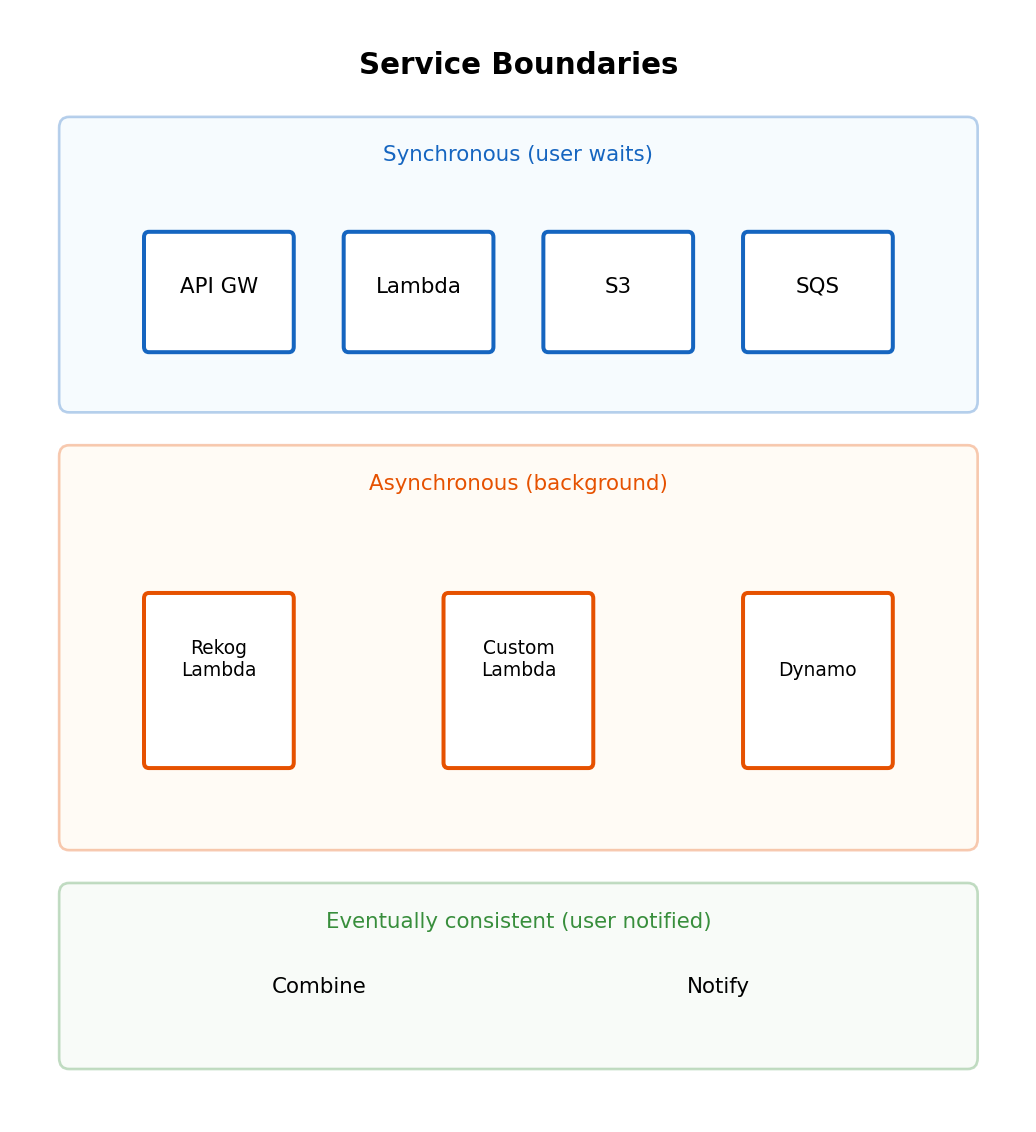
Decomposition: Identifying Service Boundaries
Start with actions, then ask: who performs each?
| Action | Characteristics | Service Candidate |
|---|---|---|
| Receive upload | HTTP, needs response | API Gateway + Lambda |
| Store original | Durable, any size | S3 |
| Queue for processing | Decouple, buffer | SQS |
| Call Rekognition | AWS SDK, fast | Lambda |
| Run custom model | CPU/memory intensive | Lambda (or container) |
| Store results | Structured query | DynamoDB |
| Combine results | Wait for both | ??? |
| Notify user | Async delivery | SNS or direct |
The interesting question: “Combine results”
Two async processes complete at different times. Something must:
- Know that both are expected
- Detect when each completes
- Trigger combination logic only when both are ready
This is the coordination problem that shapes the architecture.
The Upload Path: Synchronous Acknowledgment
User uploads image, receives job ID, can check status later
# Upload Lambda handler
def handle_upload(event, context):
# Parse multipart upload from API Gateway
body = parse_multipart(event)
image_data = body['file']
user_id = event['requestContext']['authorizer']['user_id']
# Generate job ID for tracking
job_id = str(uuid.uuid4())
# Store original in S3
s3.put_object(
Bucket=UPLOAD_BUCKET,
Key=f'uploads/{job_id}/original.jpg',
Body=image_data,
Metadata={'user_id': user_id}
)
# Create job record (pending state)
dynamodb.put_item(
TableName=JOBS_TABLE,
Item={
'job_id': {'S': job_id},
'user_id': {'S': user_id},
'status': {'S': 'pending'},
'created_at': {'S': datetime.utcnow().isoformat()}
}
)
# Queue for processing (triggers async work)
sqs.send_message(
QueueUrl=PROCESSING_QUEUE,
MessageBody=json.dumps({'job_id': job_id})
)
# Return immediately - processing happens async
return {
'statusCode': 202,
'body': json.dumps({
'job_id': job_id,
'status': 'processing',
'status_url': f'/jobs/{job_id}'
})
}HTTP 202 Accepted: Request received, processing started, result not yet available. Client has job ID to poll status.

User waits ~100-200ms for acknowledgment.
Actual analysis hasn’t started yet - only queued.
The Split: Fan-Out to Parallel Processing
SQS message triggers dispatcher Lambda
The processing queue doesn’t directly invoke both analysis paths. A dispatcher Lambda reads the message and initiates both branches.
# Dispatcher Lambda - triggered by SQS
def dispatch_handler(event, context):
for record in event['Records']:
message = json.loads(record['body'])
job_id = message['job_id']
# Get image location
image_key = f'uploads/{job_id}/original.jpg'
# Invoke Rekognition analysis (async)
lambda_client.invoke(
FunctionName='rekognition-analyzer',
InvocationType='Event', # Async - don't wait
Payload=json.dumps({
'job_id': job_id,
'image_key': image_key
})
)
# Invoke custom model analysis (async)
lambda_client.invoke(
FunctionName='custom-model-analyzer',
InvocationType='Event', # Async - don't wait
Payload=json.dumps({
'job_id': job_id,
'image_key': image_key
})
)
# Update job status
dynamodb.update_item(
TableName=JOBS_TABLE,
Key={'job_id': {'S': job_id}},
UpdateExpression='SET #s = :s',
ExpressionAttributeNames={'#s': 'status'},
ExpressionAttributeValues={':s': {'S': 'analyzing'}}
)InvocationType=‘Event’: Lambda invokes target asynchronously and returns immediately. Dispatcher doesn’t wait for either analysis to complete.
Two Lambdas now running in parallel, neither aware of the other.
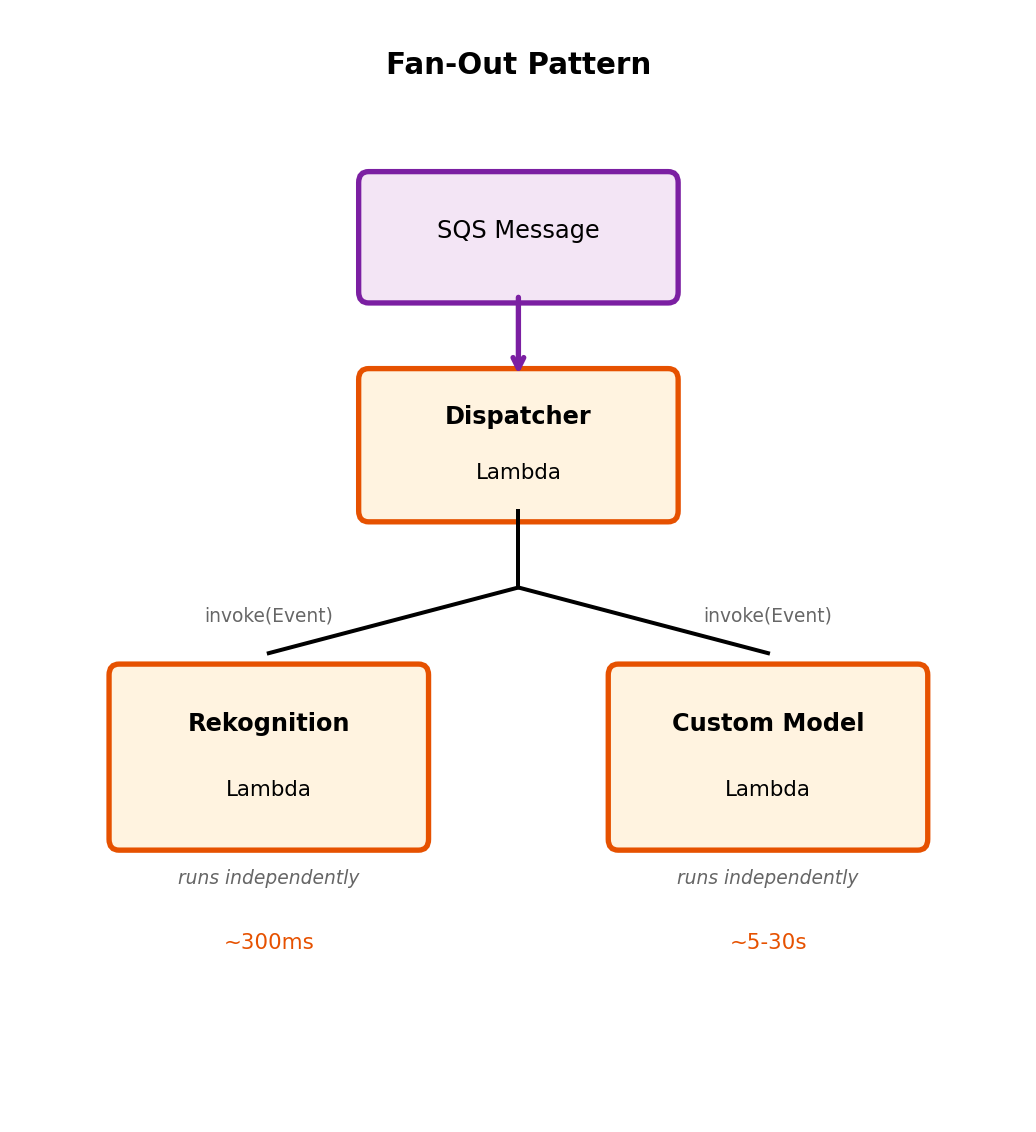
Neither analysis Lambda blocks the other.
Dispatcher completes in milliseconds.
Branch A: Calling AWS Rekognition
Rekognition is a managed service - you send image, receive labels
# Rekognition analyzer Lambda
def rekognition_handler(event, context):
job_id = event['job_id']
image_key = event['image_key']
# Call Rekognition (synchronous within this Lambda)
response = rekognition.detect_moderation_labels(
Image={
'S3Object': {
'Bucket': UPLOAD_BUCKET,
'Name': image_key
}
},
MinConfidence=70
)
# Extract results
labels = [
{
'name': label['Name'],
'confidence': label['Confidence'],
'parent': label.get('ParentName', '')
}
for label in response['ModerationLabels']
]
# Store results in DynamoDB
dynamodb.update_item(
TableName=JOBS_TABLE,
Key={'job_id': {'S': job_id}},
UpdateExpression='SET rekognition_result = :r, rekognition_at = :t',
ExpressionAttributeValues={
':r': {'S': json.dumps(labels)},
':t': {'S': datetime.utcnow().isoformat()}
}
)
# Check if other branch is complete
check_and_finalize(job_id)Rekognition returns structured data:
- Moderation labels (violence, explicit content, etc.)
- Confidence scores
- Label hierarchy (parent categories)
This Lambda writes its results and then checks if the job can be finalized.
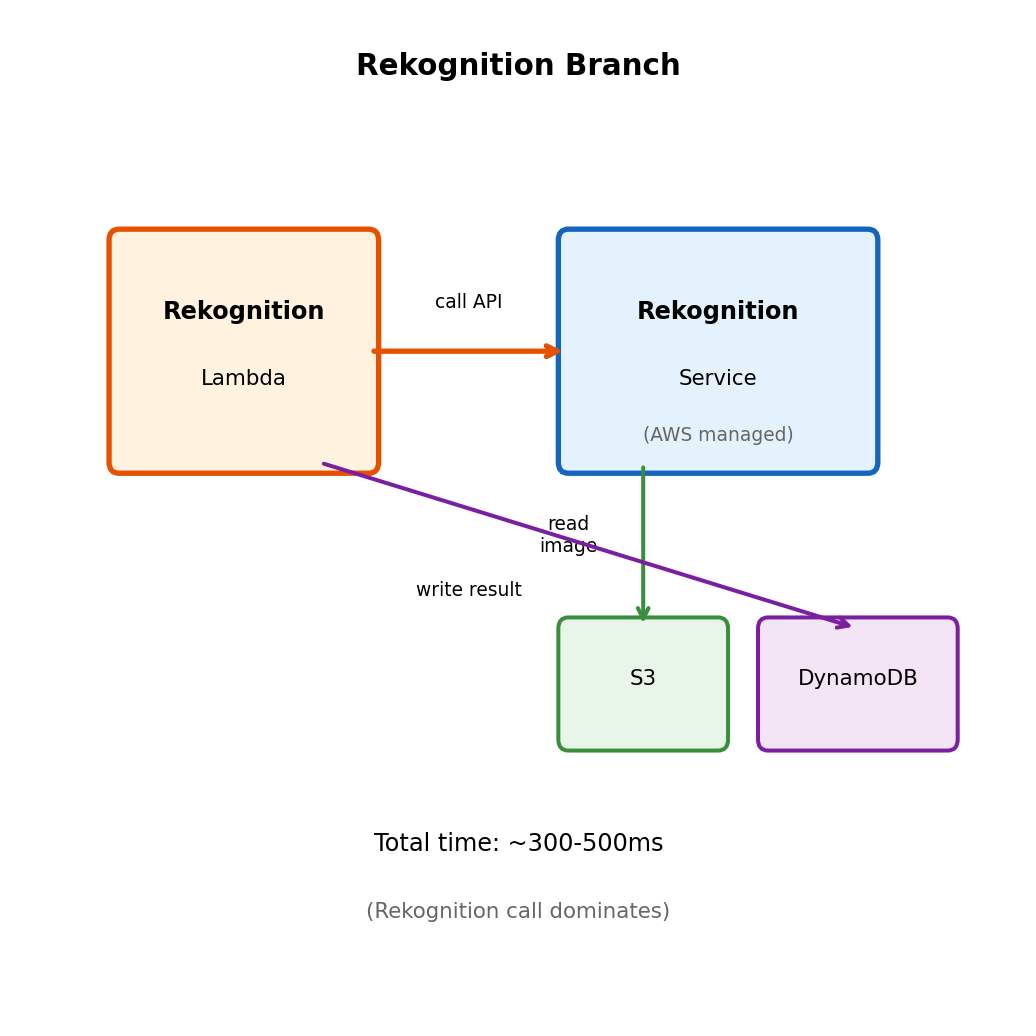
Rekognition reads directly from S3 - image bytes don’t flow through Lambda.
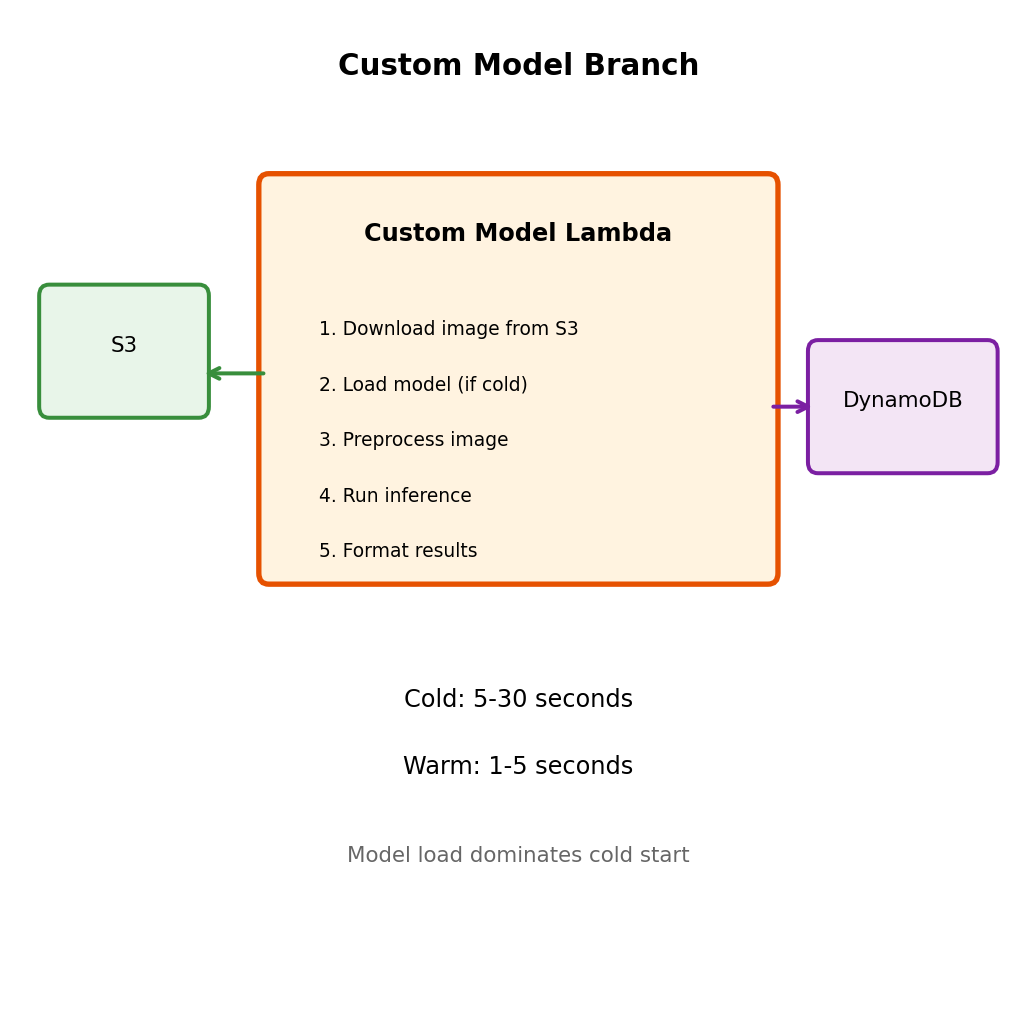
Branch B: Custom Model Analysis
Your own classification logic - runs longer, under your control
# Custom model analyzer Lambda
def custom_model_handler(event, context):
job_id = event['job_id']
image_key = event['image_key']
# Download image from S3
response = s3.get_object(Bucket=UPLOAD_BUCKET, Key=image_key)
image_bytes = response['Body'].read()
# Load model (cached in execution environment)
model = get_cached_model()
# Preprocess image
tensor = preprocess_image(image_bytes)
# Run inference
predictions = model.predict(tensor)
# Post-process results
categories = [
{
'category': CATEGORY_NAMES[i],
'score': float(predictions[i])
}
for i in range(len(predictions))
if predictions[i] > 0.5
]
# Store results
dynamodb.update_item(
TableName=JOBS_TABLE,
Key={'job_id': {'S': job_id}},
UpdateExpression='SET custom_result = :r, custom_at = :t',
ExpressionAttributeValues={
':r': {'S': json.dumps(categories)},
':t': {'S': datetime.utcnow().isoformat()}
}
)
# Check if other branch is complete
check_and_finalize(job_id)Time breakdown:
- S3 download: ~50-200ms
- Model loading (cold): ~2-10s
- Model loading (warm): ~0ms (cached)
- Inference: ~500ms-5s (depends on model)
Cold start dominates. Warm invocations much faster.
All compute happens inside Lambda.
Memory setting affects inference speed (more memory = more CPU).
The Coordination Problem: When Are Both Done?
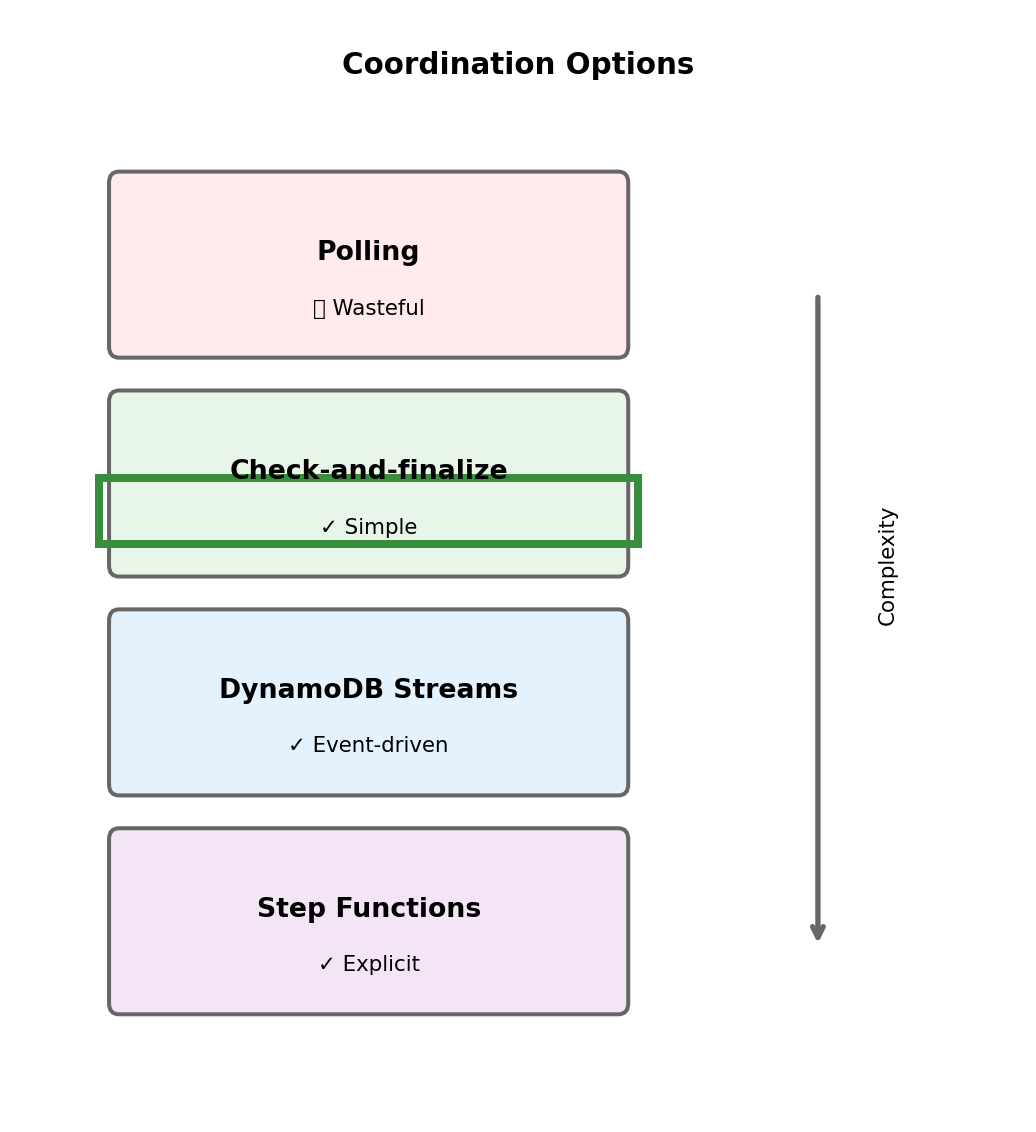
Both branches write results to DynamoDB. How do we know when both are complete?
Option 1: Polling
Status check Lambda queries DynamoDB periodically. When both results present, trigger finalization.
- Simple but wasteful
- Latency depends on poll interval
- Works but not elegant
Option 2: Each branch checks and finalizes
After writing its result, each branch checks if the other result exists. First to see both results triggers finalization.
- Event-driven, no polling
- Exactly one branch triggers finalization (with proper locking)
- Race condition must be handled
Option 3: DynamoDB Streams
DynamoDB stream triggers Lambda on every update. Lambda checks if both results present.
- Fully event-driven
- Additional complexity (stream processing)
- Natural fit for DynamoDB-centric architecture
Option 4: Step Functions
State machine waits for both branches, then proceeds.
- Cleanest coordination model
- Additional service and cost
- Explicit workflow representation
We’ll implement Option 2 - simple, no additional services.
For this example: Check-and-finalize.
Production systems often use Step Functions for complex workflows.
Implementing Check-and-Finalize
Each branch calls this after writing its result:
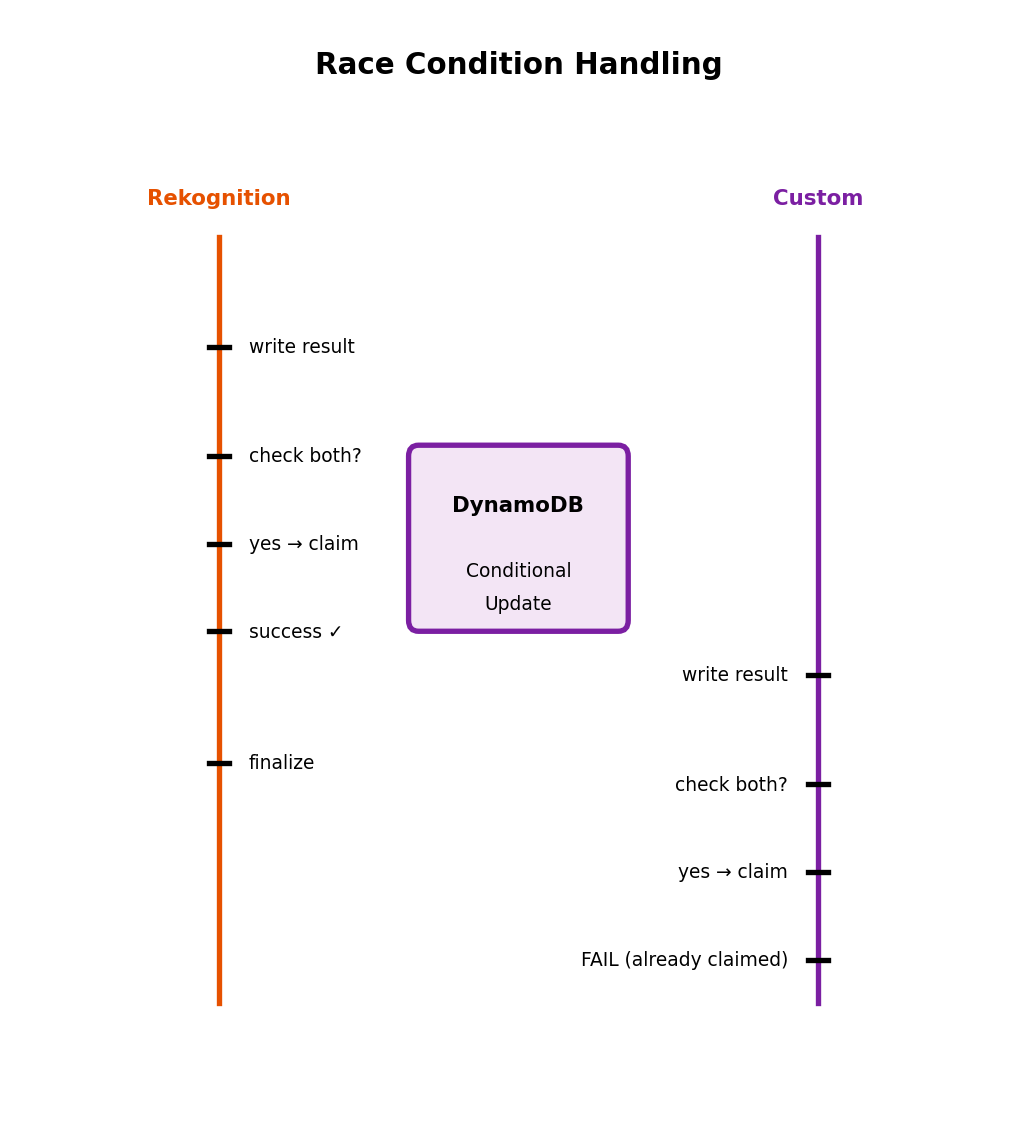
def check_and_finalize(job_id):
# Atomic read of current state
response = dynamodb.get_item(
TableName=JOBS_TABLE,
Key={'job_id': {'S': job_id}},
ConsistentRead=True # Strong consistency required
)
item = response.get('Item', {})
# Check if both results present
has_rekognition = 'rekognition_result' in item
has_custom = 'custom_result' in item
if not (has_rekognition and has_custom):
# Other branch not done yet - nothing to do
return
# Both done - try to claim finalization
# Conditional update prevents double-finalization
try:
dynamodb.update_item(
TableName=JOBS_TABLE,
Key={'job_id': {'S': job_id}},
UpdateExpression='SET #s = :s, finalized_at = :t',
ConditionExpression='#s <> :done',
ExpressionAttributeNames={'#s': 'status'},
ExpressionAttributeValues={
':s': {'S': 'finalizing'},
':done': {'S': 'complete'}
}
)
except dynamodb.exceptions.ConditionalCheckFailedException:
# Other branch already claimed finalization
return
# We claimed it - do the finalization
finalize_job(job_id, item)ConditionExpression ensures only one branch finalizes, even if both check simultaneously.
DynamoDB conditional update is atomic.
Only one branch wins the race.
Finalization: Combining Results
The branch that claims finalization combines results and determines outcome:
def finalize_job(job_id, item):
# Parse both results
rekognition = json.loads(item['rekognition_result']['S'])
custom = json.loads(item['custom_result']['S'])
# Business logic: combine analysis
decision = make_moderation_decision(rekognition, custom)
# Update final status
dynamodb.update_item(
TableName=JOBS_TABLE,
Key={'job_id': {'S': job_id}},
UpdateExpression='''
SET #s = :status,
decision = :decision,
completed_at = :time
''',
ExpressionAttributeNames={'#s': 'status'},
ExpressionAttributeValues={
':status': {'S': 'complete'},
':decision': {'S': json.dumps(decision)},
':time': {'S': datetime.utcnow().isoformat()}
}
)
# Notify user (async)
sns.publish(
TopicArn=NOTIFICATION_TOPIC,
Message=json.dumps({
'job_id': job_id,
'user_id': item['user_id']['S'],
'decision': decision
})
)Decision logic is application-specific:
- Rekognition flags explicit content → reject
- Custom model flags off-topic → warn
- Neither flags issues → approve
- Conflicting signals → manual review queue
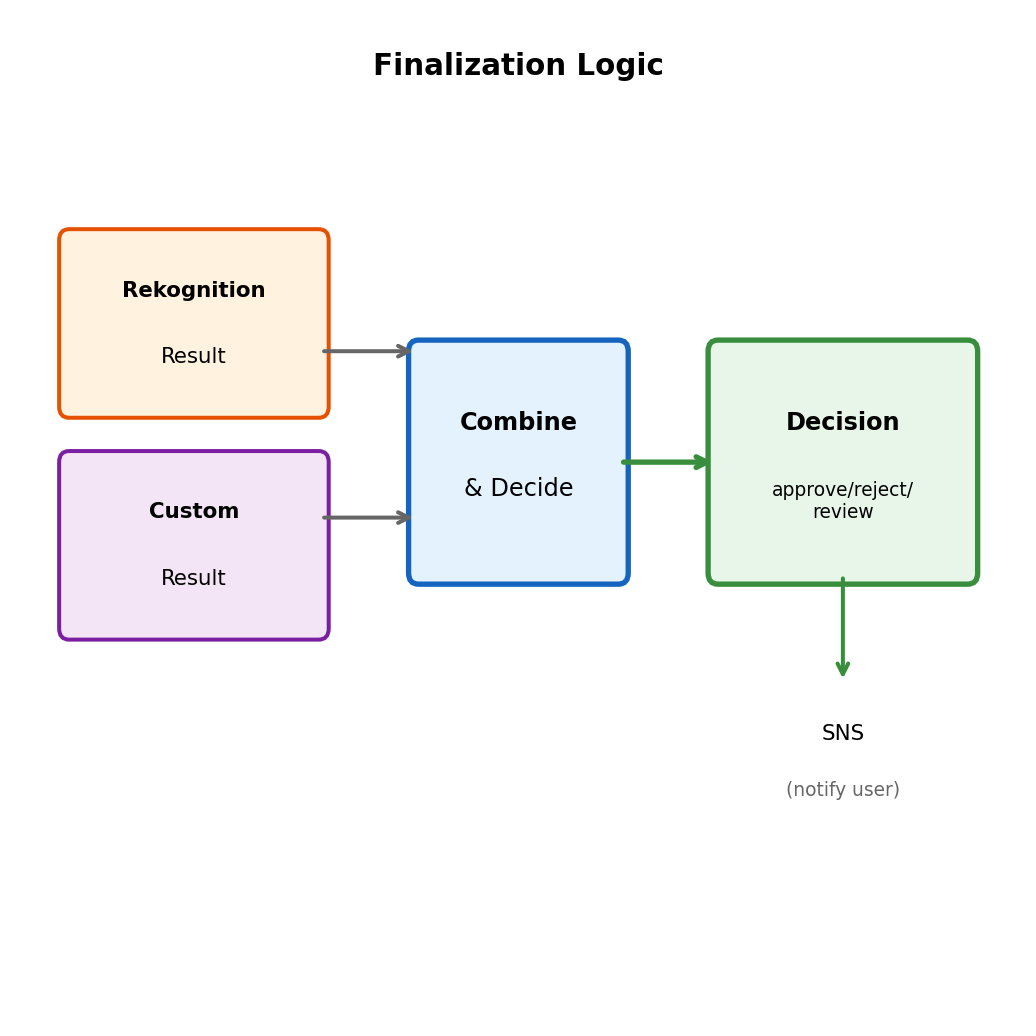
Business logic concentrated in one place.
Easy to modify decision rules without changing pipeline structure.
Complete Data Flow
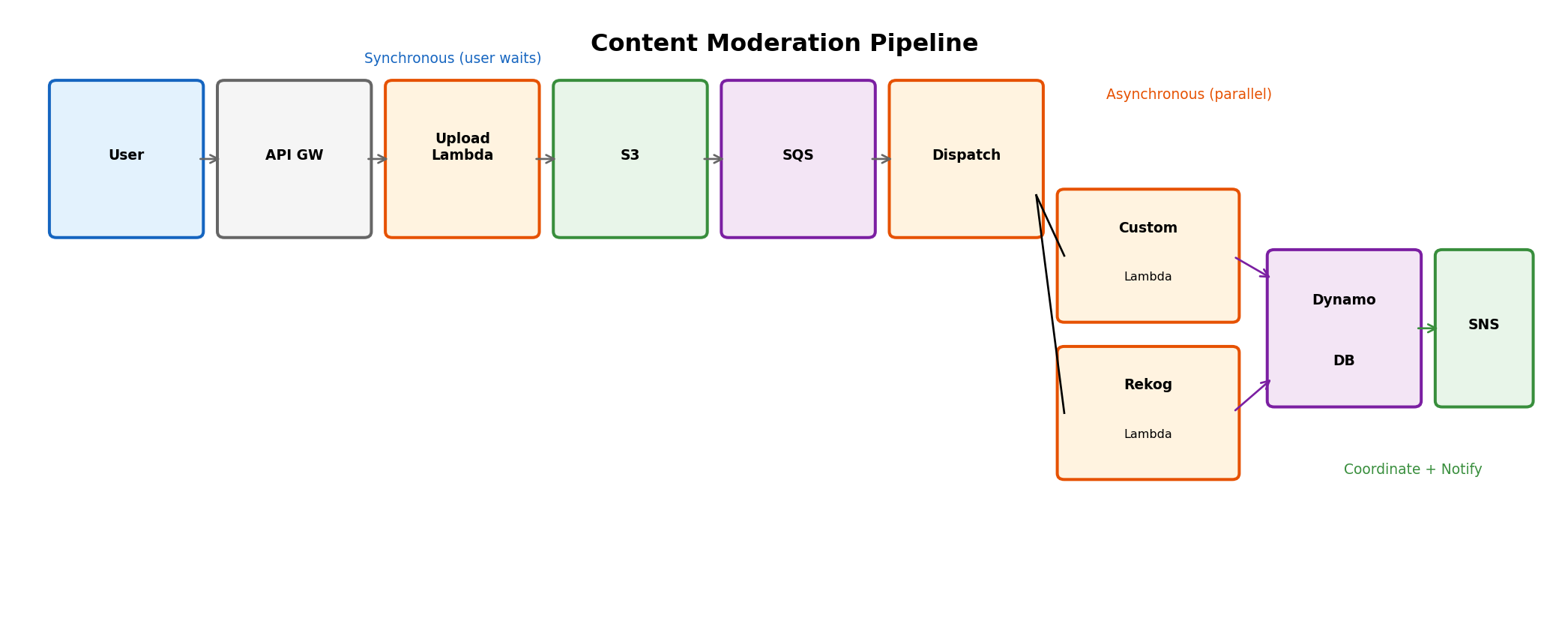
Seven services, one pipeline:
- API Gateway → receives HTTP, routes to Lambda
- Upload Lambda → validates, stores, queues (sync response)
- S3 → holds image bytes durably
- SQS → decouples upload from processing
- Dispatcher Lambda → fans out to both analysis paths
- Analysis Lambdas → Rekognition + Custom model (parallel)
- DynamoDB → holds state, coordinates completion
- SNS → delivers notification
Failure Modes and Recovery
Each service boundary is a potential failure point
| Failure | Impact | Recovery |
|---|---|---|
| Upload Lambda timeout | User sees error | Retry upload |
| S3 put fails | No image stored | Lambda retries, fails to user |
| SQS send fails | Job stuck pending | Lambda retries, DLQ if persistent |
| Dispatcher fails | Job stuck analyzing | SQS retry, DLQ |
| Rekognition fails | Partial results | DLQ, manual intervention |
| Custom model fails | Partial results | DLQ, manual intervention |
| DynamoDB fails | State lost | Retry, eventual consistency |
Dead Letter Queues capture persistent failures:
# SQS queue configuration
{
"RedrivePolicy": {
"deadLetterTargetArn": "arn:aws:sqs:...:processing-dlq",
"maxReceiveCount": 3
}
}Message fails 3 times → moves to DLQ. Operations team investigates.
Partial completion is the hard case:
Rekognition succeeds, custom model fails. Job has one result but not both. Options:
- Timeout and notify failure after N minutes
- DynamoDB TTL cleans up orphaned jobs
- Monitoring alerts on jobs stuck in “analyzing” state
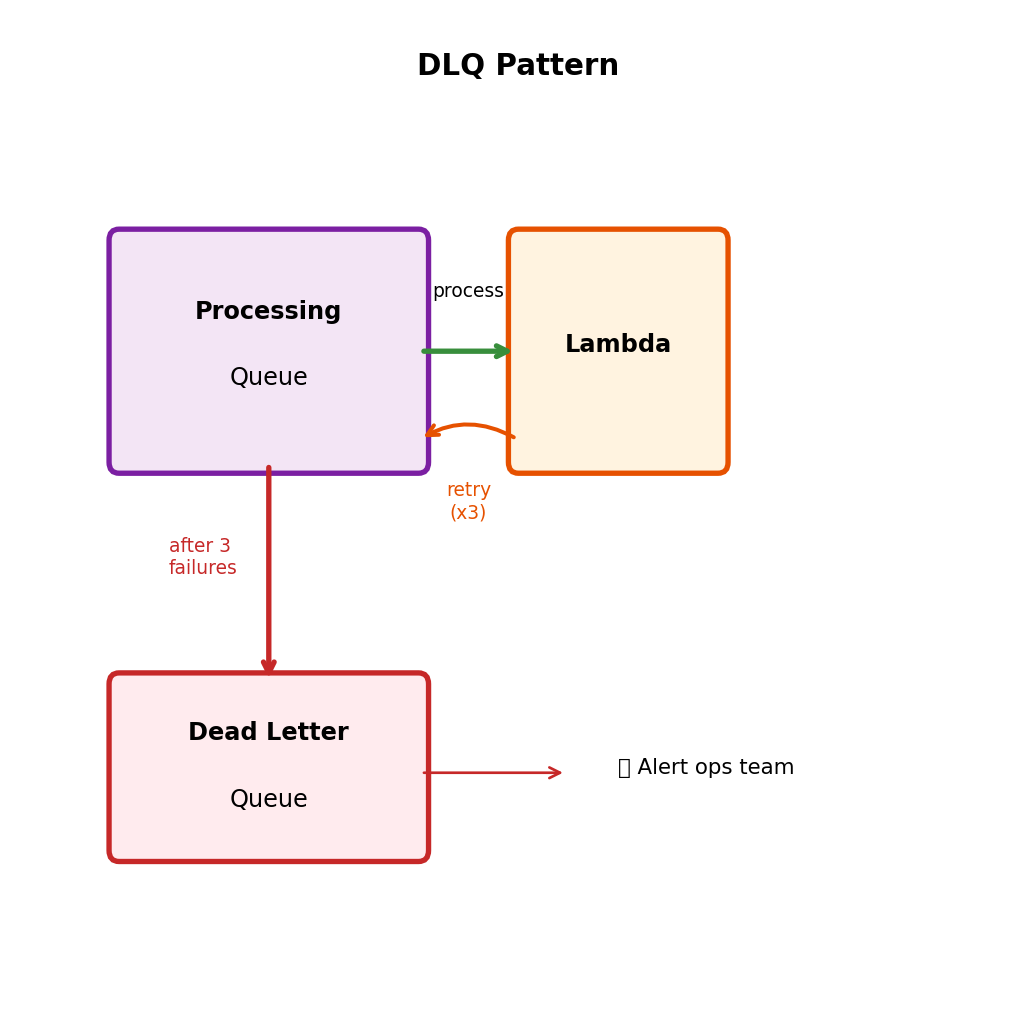
Messages that consistently fail don’t block the queue.
DLQ preserves evidence for debugging.
Observability: Understanding the Pipeline
Each Lambda writes structured logs:
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def log_event(event_type, job_id, **kwargs):
logger.info(json.dumps({
'event': event_type,
'job_id': job_id,
'timestamp': datetime.utcnow().isoformat(),
**kwargs
}))
# Usage in handlers
log_event('upload_received', job_id, size_bytes=len(image_data))
log_event('rekognition_complete', job_id, label_count=len(labels))
log_event('finalization_claimed', job_id, claimed_by='rekognition')job_id is the correlation key:
All logs for one upload share the same job_id. Query CloudWatch Logs:
fields @timestamp, event, @message
| filter job_id = "abc-123-def"
| sort @timestamp ascKey metrics to track:
- Queue depth (SQS): Are we keeping up?
- Lambda duration: Cold starts? Slow inference?
- Error rate by stage: Where do failures concentrate?
- End-to-end latency: Upload to notification time

One job_id links all events.
Async gap visible in timestamps.
Extending the Pattern
Same structure, different domains:
Document processing pipeline:
- Upload: PDF document
- Branch A: Textract (AWS OCR)
- Branch B: Custom NLP model
- Combine: Extracted text + entity classification
Video analysis pipeline:
- Upload: Video file
- Branch A: Rekognition Video (scene detection)
- Branch B: Transcribe (audio to text)
- Branch C: Custom model (brand detection)
- Combine: Multi-modal analysis result
The pattern generalizes:
- Receive input (sync acknowledgment)
- Fan-out to parallel processors
- Each processor writes partial result
- Coordination point combines results
- Deliver final output
Coordination complexity scales with branches:
- 2 branches: Check-and-finalize works
- 3+ branches: Consider Step Functions
- Dynamic branches: Definitely Step Functions
Pattern scales horizontally.
Coordination strategy must match branch count.